
TL;DR
데이터베이스를 운영하다보면, 데이터가 추가되면서 테이블 간의 관계가 복잡해져 그 관리가 어려워질 수 있다.
이 포스트에서는 Marco Perone의 글을 바탕으로 데이터베이스 내 테이블들의 관계를 그래프로 나타내어 보면, 데이터베이스 관리에 있어 어떤 유용한 인사이트를 얻을 수 있는 지 알아본다.
원문 링크: https://marcosh.github.io/post/2016/09/15/db-graph-analisys.html
* 의역이 있을 수 있습니다.
Database relations and graph visualization
데이터베이스 테이블 관계를 그래프로 시각화하기
프로젝트의 크기가 점점 커질 때, 이를 여러 개의 하위 프로젝트로 분할하는 것이 바람직한 시점까지 성장하는 경우가 종종 있다. 이렇게 프로젝트를 분할하면, 작고 독립적이며 유지보수가 용이한 구성 요소(component)를 만들 수 있고, 하위 단계에서 병렬로 작업하기가 더 쉬워진다. 하지만, 대규모의 프로젝트를 의미를 가지면서 독립적인 하위 프로젝트로 분할하는 방법을 이해하는 것은 쉽지 않다.
프로젝트 분할을 위한 첫 번째 단계는 시스템을 점검하고 구성 요소 간의 관계를 분석하는 것이다. 어떤 구성 요소가 애플리케이션의 나머지 부분과 느슨하게 결합되어 있다면, 그 자체로 독립적인 서비스가 될 수 있는 좋은 후보가 될 것이다.
그렇다면 프로젝트의 모든 구성 요소 간의 관계를 어떻게 시각화하고 분석할 수 있을까? 데이터 지속성(persistance)을 위해 관계형 데이터베이스(relational databases)를 사용하고 있다면 이러한 관계를 찾을 수 있는 방법이 있다.
Database relations
데이터베이스 관계
RDB에서는 테이블 간의 외래 키(foreign key)를 관계로 볼 수 있다. 예를 들어, 고객($customer$) 테이블에 외래 키가 있고 자동차($car$) 테이블에 외래 키가 있는 여행($trip$) 테이블이 있다면 여행의 개념이 고객과 자동차의 개념에 따라 달라진다는 것을 쉽게 추론할 수 있다.
즉, 데이터베이스를 방향성 그래프(directed graph)로 시각화할 수 있다. 여기서 정점(vertices)는 데이터베이스의 테이블이며 $A$ 테이블에 $B$ 테이블을 참조하는 외래 키가 있는 경우 $A$ 테이블에서 $B$ 테이블로 연결되는 간선(edges)이 생성된다.
이 그래프를 생성하는 데 필요한 데이터를 얻으려면, 다음의 쿼리를 실행하면 된다(PostgreSQL 기준).
SELECT
tc.table_name,
ccu.table_name AS foreign_table_name
FROM
information_schema.table_constraints AS tc
JOIN information_schema.constraint_column_usage AS ccu
ON ccu.constraint_name = tc.constraint_name
WHERE constraint_type = 'FOREIGN KEY'
GROUP BY tc.table_name, foreign_table_name;
이를 실행하면 테이블명 쌍(pair)의 목록이 생성되며, 각 쌍은 첫 번째 테이블에서 두 번째 테이블로 연결되는 간선을 나타낸다.
Visualize the graph
그래프 시각화
쿼리 결과 데이터를 csv 파일 등으로 export한 후, 이를 Gephi와 같은 그래프 분석 도구로 import할 수 있다. 이렇게 하면, 다음과 같은 그래프를 얻을 수 있다.
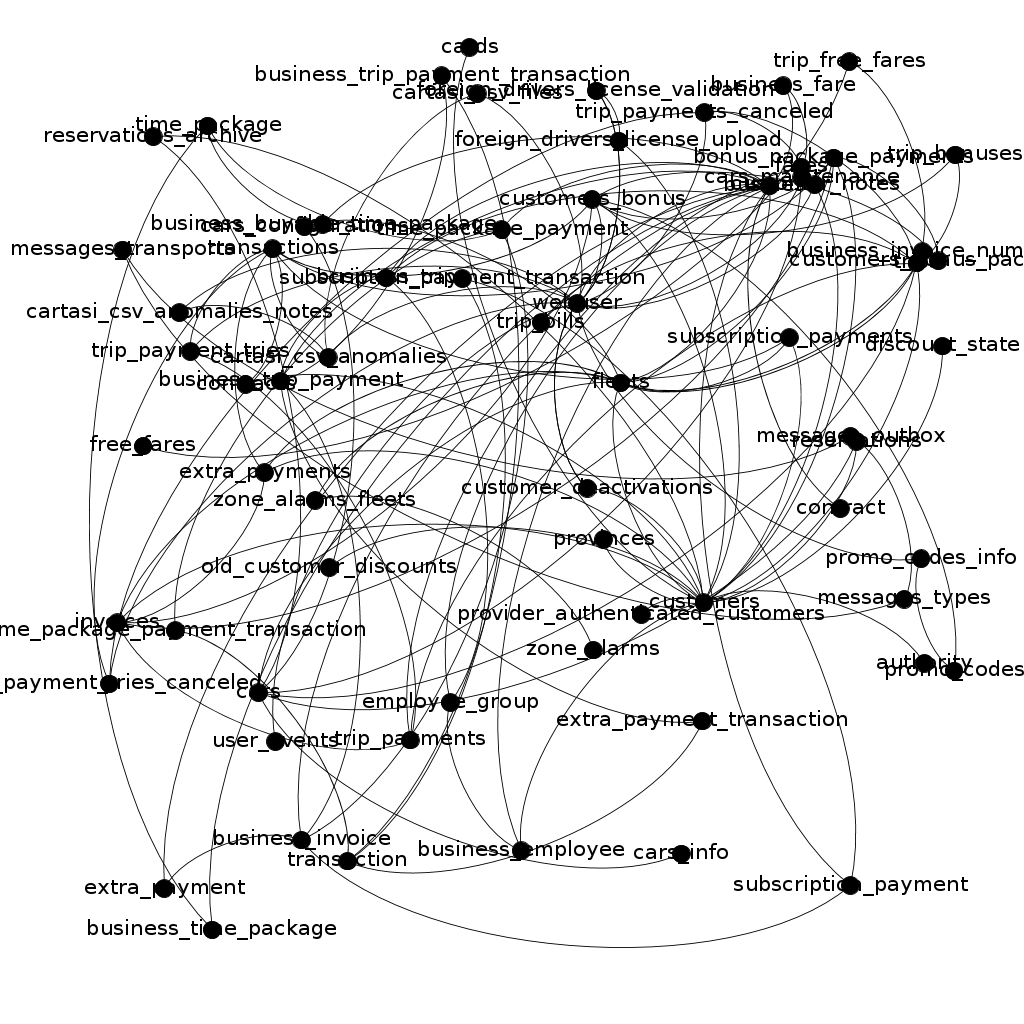
이 상태로는, 그다지 유용한 인사이트를 찾기 힘들다. 좀 더 가독성 있는 그래프를 얻으려면 Gephi의 기능을 사용해야 한다. 예를 들어, $Force\ Atlas$, $Expansion$, $Label\ Adjust$과 같은 레이아웃을 사용하여 그래프를 표현하면 다음과 같은 결과를 얻을 수 있다.
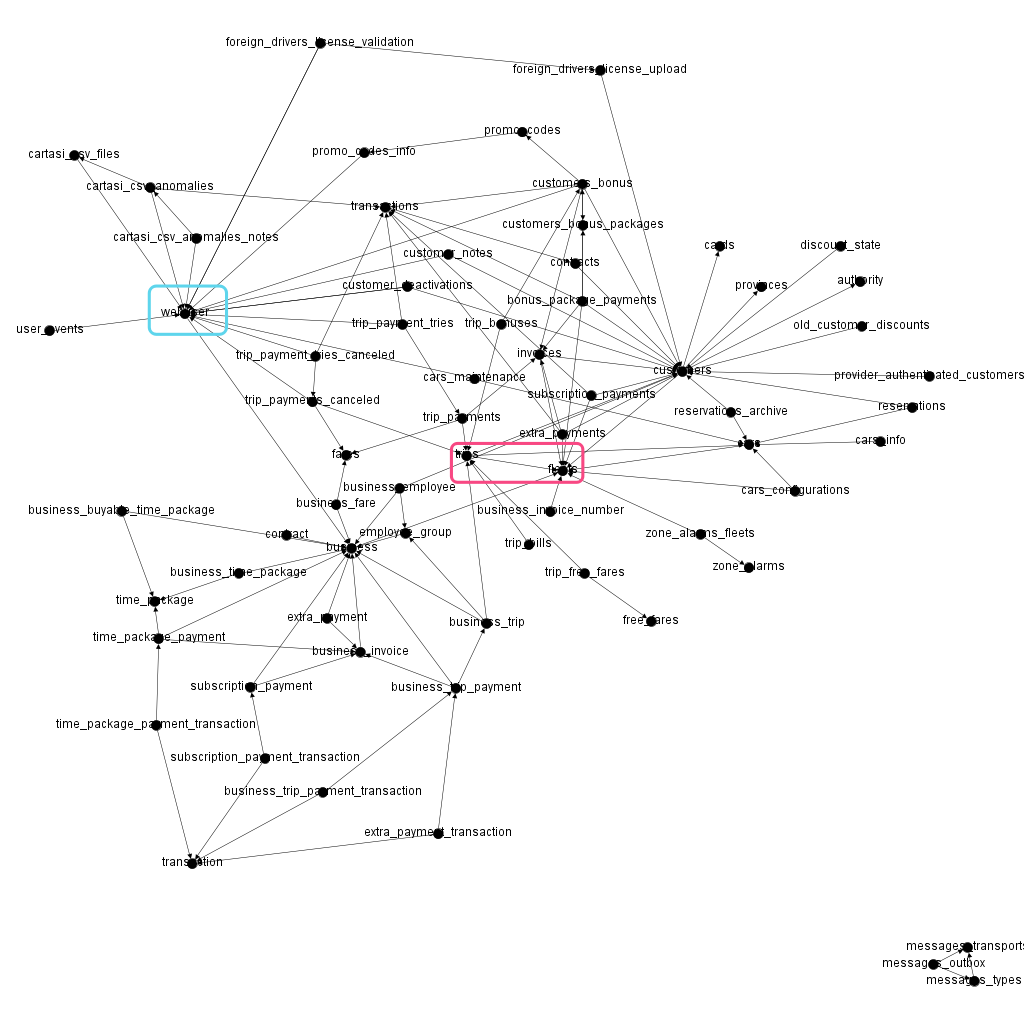
이전의 그래프보다 훨씬 보기가 좋아졌다. 오른쪽 하단에서, 나머지 모든 애플리케이션과 전혀 관련이 없는 세 개의 테이블이 있음을 곧바로 확인할 수 있다. 이는 아마도 시스템의 나머지 부분과 쉽게 분리될 수 있는 구성 요소일 것이다.
이 외에도, 도메인에 대한 지식을 활용하여 수동으로 그래프를 개선할 수 있다. 이를 통해 도메인 모델을 더 잘 나타낼 수 있다. 예를 들어, 실제로 도메인의 entity를 나타내지 않는 테이블을 그래프에서 제거할 수 있다.
위 그래프의 경우, 웹사용자($webuser$) 테이블(푸른 사각형)은 연결된 작업(operation)들에서 해당 작업의 수행자가 누구인지 저장하기 때문에 다른 많은 테이블에 연결되어 있다. 이러한 구성 방식은, 도메인을 표현하는 데에 노이즈만 발생시키므로 해당 테이블을 제거하는 것이 좋다.
또 다른 방법으로, 도메인 수준에서 실제 관계를 나타내지 않는 일부 간선을 제거하여 그래프를 정리할 수 있다. 예를 들어, 여행($trips$) 테이블에서 $fleets$ 테이블로 가는 화살표가 있는데(붉은 사각형), 이는 모든 여행에 대해 해당 여행에 사용된 차량의 차량 수를 저장한다는 의미이다.
이미 여행과 차량, 차량과 차량 간의 관계가 있기 때문에 이 가장자리는 불필요하다*. 이런 식으로 분석과 관련이 없는 다른 에지를 제거하면 다음과 같은 결과를 얻을 수 있습니다.
* 이는 도메인 지식을 함께 활용하여 판단하는 예제로 볼 수 있다.
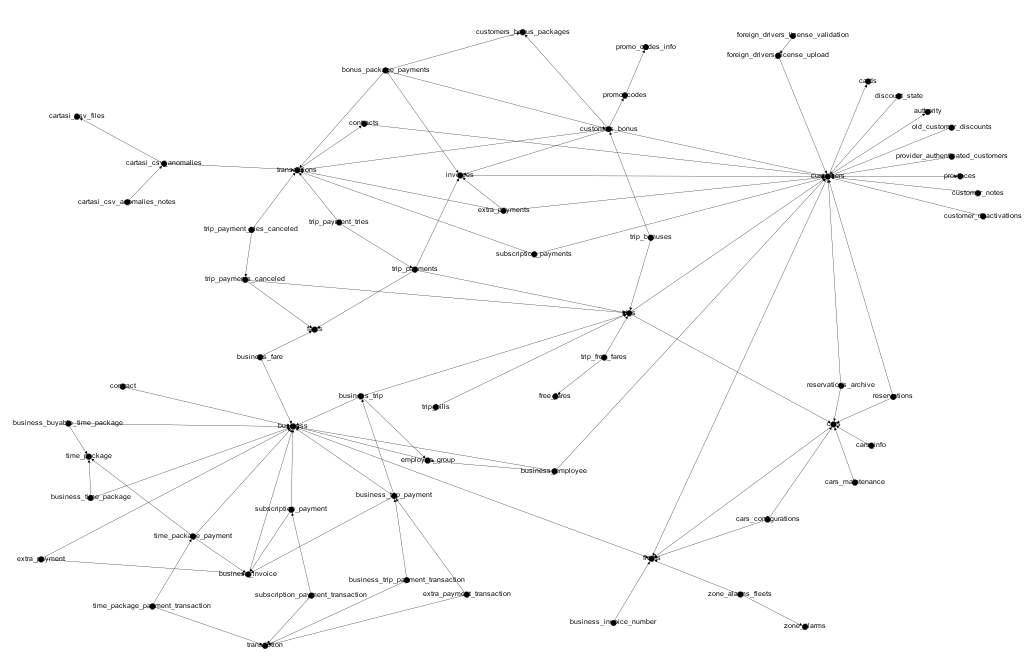
이 그래프에서 몇 개의 서로 긴밀하게 연결된 테이블 그룹을 관찰할 수 있는데, 이러한 그룹들은 별도의 하위 프로젝트로 분리할 수 있는 구성 요소가 될 수 있다. 반면, 다양한 구성 요소가 매우 긴밀하게 연결되어 있는 경우는 일부분을 별도의 하위 프로젝트로 분리하는 것이 어려울 수 있다.
Conclusions
결론
관계형 데이터베이스에서 테이블의 관계를 이용해 주어진 그래프를 분석하면, 프로젝트를 여러 구성 요소로 분할하려고 할 때 이러한 구성 요소들이 서로 어떻게 연결되어 있는지 알 수 있어 유용하다. 이 그래프를 통해, 도메인에 적용된 모델*에 존재하는 인사이트를 발견하고 이에 대한 올바른 관리 방법을 제안할 수 있다.
* 맥락 상 모델이란 단어는, 도메인을 데이터베이스로 표현하는 스키마(schema) 모델로 이해할 수 있다.
이는 데이터 중심의 접근 방식이며, 데이터베이스의 구조에만 집중하다 보면 많은 세부 사항을 놓칠 수 있다. 그래프는 분석을 시작하고 도메인의 현재 모델을 대략적으로 표현하기 위한 출발점일 뿐이다. 분석을 더 진행하려면 도메인에 대한 다른 이해의 원천이 반드시 필요하다. 분석을 성공적으로 완료하려면 도메인을 운영하는 회사의 경험과, 도메인 전문가의 경험이 필수적일 것이다.
마치며
많은 데이터베이스에서도 ERD(Entity-Relation Diagram)를 통해 스키마를 시각화할 수 있지만, 이는 단순한 형태의 시각화만 가능하여 분석에 대한 인사이트를 얻기 어렵다.
반면, 그래프 분석 모듈을 이용하면 테이블 관계를 다양한 시각화 레이아웃으로 볼 수 있어 인사이트를 찾기가 용이하다.
물론, 이러한 인사이트는 그래프로 나타낸다고 해서 곧바로 도출되는 것은 아니며 충분한 도메인 지식이 필요할 것으로 보인다.
'🟢 GraphML' 카테고리의 다른 글
| 콜로니 그래프(Colony Graph): 클라우드 서비스를 시각화하기 - 02 (0) | 2024.03.11 |
|---|---|
| 콜로니 그래프(Colony Graph): 클라우드 서비스를 시각화하기 - 01 (0) | 2024.03.10 |


댓글