
TL;DR
본 포스트에서는, Postgres가 강력한 확장 기능과 오픈 소스의 강점을 살려 데이터베이스 시장을 지배하고 있다는 내용의 'Pigsty' 서비스의 개발자 Vonng이 작성한 아티클을 번역하였다. 원문에서는 여기서 나아가 Postgres가 해결해야 할 과제를 함께 제시하고 그 대안으로 Pigsty의 필요성을 강조하고 있다.
원문 링크: https://medium.com/@fengruohang/postgres-is-eating-the-database-world-157c204dcfc4
Postgres is eating the database world
PostgreSQL isn’t just a simple relational database; it’s a data management framework with the potential to engulf the entire database…
medium.com
*이해를 돕기 위한 의역이 포함될 수 있습니다.
Postgres is eating the database world
2024-03-16, by Vonng
PostgreSQL은 단순한 관계형 데이터베이스가 아니라, 전체 데이터베이스 영역을 아우를 수 있는 잠재력을 지닌 데이터 관리 프레임워크다. '모든 것에 사용되는 Postgres'라는 트렌드는 더 이상 소수의 엘리트 팀에만 국한된 것이 아닌 주류 집단의(mainstream) 모범 사례가 되고 있다.
OLAP의 새로운 도전자
2016년 데이터베이스 밋업에서, 필자는 PostgreSQL 생태계가 따라잡아야 할 중요한 격차는 OLAP 워크로드를 위한 충분히 우수한 컬럼형 스토리지 엔진의 부재라고 주장했다. PostgreSQL 자체는 많은 분석 기능을 제공하지만, 대규모 데이터 세트에 대한 본격적인 분석 성능은 전용 실시간 데이터 웨어하우스에 미치지 못한다.
분석 성능의 벤치마크인 ClickBench는 PostgreSQL, 그 생태계 확장 및 파생 데이터베이스의 성능을 문서화한 것이다. 튜닝되지 않은 PostgreSQL은 저조한 성능을 보이지만(x1050), 최적화를 통해 (x47) 수준 성능까지 도달할 수 있다. 또한, 세 가지 분석 관련 확장 기능(extensions)으로 컬럼형 저장소 Hydra(x42), 시계열 저장소 TimeScaleDB(x103), 분산형 저장소 Citus(x262)가 존재한다.
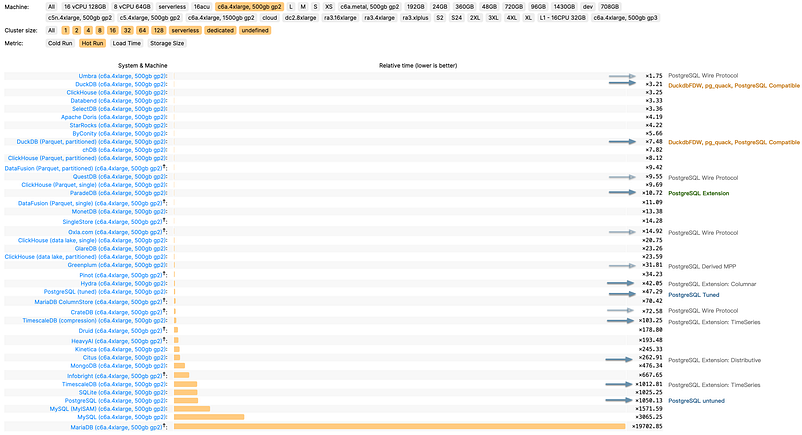
이 성능은 MySQL, MariaDB(x3065, x19700)와 같은 순수 OLTP 데이터베이스와 비교하면 나쁘다고 볼 수 없지만, 3계층 성능은 Umbra, ClickHouse, Databend, SelectDB(x3~x4)와 같은 1계층 OLAP 구성 요소보다 크게 뒤쳐져 충분하지는 않은 수준이다. 사용하기에는 만족스럽지 않지만 버리기에는 아쉬운, 사용 판단이 어려운 수준의 성능이다.
하지만, ParadeDB와 DuckDB의 등장으로 판도가 바뀌었다. ParadeDB의 기본 PG 확장 프로그램인 pg_analytics는 두 번째 계층의 성능(x10)을 달성하여 상위 계층과의 격차를 불과 3~4배로 좁혔다. 다양한 기능으로 인한 추가적인 장점을 고려할 때, 이 정도의 성능 차이는 어느 정도 수용 가능한 수준이다. 이러한 추가적인 장점으로는 대표적으로 ElasticSearch 수준의 전체 텍스트(full-text) 검색 기능이 있으며, 추가적인 학습 장벽이나 별도의 서비스 유지 관리가 필요 없는 ACID, 최신 데이터 유지(freshness) 및 ETL이 필요 없는 실시간 데이터 유지 등이 있다.
순수 OLAP에 중점을 두고 분석 성능을 극한까지 끌어올린 DuckDB는, 학문적 용도에 초점을 맞춘 비공개 소스 데이터베이스 Umbra를 제외하면 실용적인 OLAP 성능에서 가장 빠르다(x3.2). PG의 확장 기능은 아니지만, PostgreSQL은 임베디드 파일 데이터베이스인 DuckDB의 향상된 분석 성능을 DuckDB FDW 및 pg_quack과 같은 프로젝트를 통해 충분히 활용할 수 있다.
ParadeDB와 DuckDB가 등장하면서 분석 성능의 마지막 중요한 격차를 메웠고, PostgreSQL의 분석 기능은 OLAP의 최상위 계층으로 올라섰다.
데이터베이스 분야의 진자(Pendulum)
데이터베이스의 초창기에는 OLTP와 OLAP의 구분이 존재하지 않았다. 데이터베이스에서 OLAP 데이터 웨어하우스가 분리된 것은, 1990년대에 기존 OLTP 데이터베이스가 분석 시나리오의 쿼리 패턴과 성능 요구 사항을 지원하는 데에 어려움을 겪으면서부터이다.
오랫동안 데이터 처리의 모범 사례는, OLTP 워크로드에 MySQL/PostgreSQL을 사용하고 ETL 프로세스를 통해 데이터를 Greenplum, ClickHouse, Doris, Snowflake 등과 같은 전문 OLAP 시스템으로 동기화하는 것이었다.

많은 전문(specialized) 데이터베이스와 마찬가지로, 전용 OLAP 시스템의 강점은 네이티브 PostgreSQL이나 MySQL보다 1~3배 향상된 성능에 있는 경우가 많았다. 그러나 그 대가로 데이터 중복, 과도한 데이터 이동, 분산된 구성 요소 간의 데이터 값에 대한 합의(agreement) 부족, 전문 기술에 대한 추가 인건비, 추가 라이선스 비용, 제한된 쿼리 언어 능력, 프로그래밍이나 확장성의 한계, 제한적인 도구 통합(tool integration), 완전한 DBMS에 비해 낮은 데이터 무결성 및 가용성 등의 문제가 발생할 수 있었다.
하지만, '돌고 도는 것은 결국 다시 돌아온다(What goes around comes around)'는 속담이 있다. 무어의 법칙에 따라 30년 이상 하드웨어가 개선되면서, 성능은 기하급수적으로 증가한 반면 비용은 급감했다. 2024년에는 단일 x86 서버에 수백 개의 코어(512 vCPU, EPYC 9754 x2), 수 TB의 RAM, 단일 NVMe SSD에 최대 64TB/3M 4K 랜드 IOPS/14GB/초, 단일 올-플래시(single all-flash) 랙이 수 PB에 달하고, Amazon S3 같은 객체(object) 스토리지는 사실상 무제한의 스토리지를 제공할 수 있게 될 것이다.
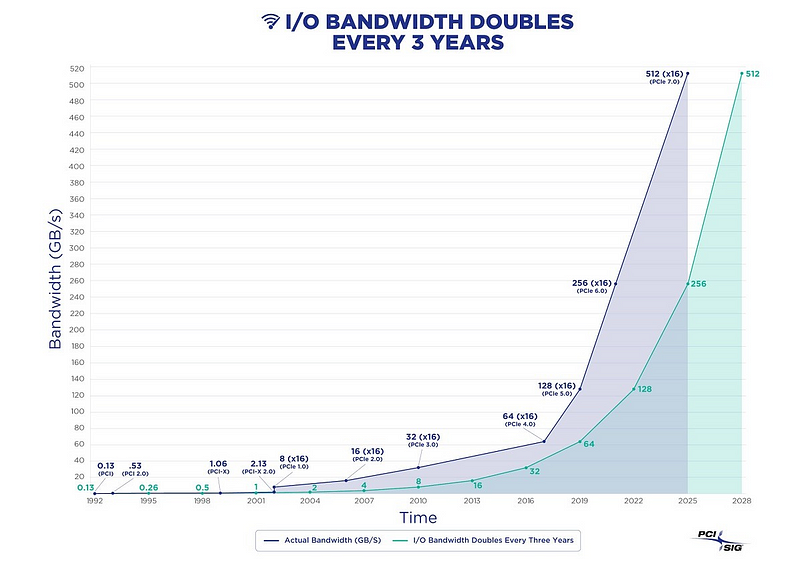
하드웨어의 발전으로 데이터의 양과 성능 문제가 해결되었고, 데이터베이스 소프트웨어(PostgreSQL, ParadeDB, DuckDB)의 발전으로 액세스 방법의 문제도 해결되었다. 이로 인해 소위 '빅데이터' 산업이라 불리는 분석 부문의 일반적인 가정들은 다시 검토되고 있다.
DuckDB가 '빅데이터는 죽었다'고 선언한 데에서 알 수 있듯이 빅데이터의 시대는 끝났다. 대부분의 사람들은 그렇게 많은 데이터를 가지고 있지 않으며, 대부분의 데이터는 거의 쿼리되지도 않는다. 하드웨어와 소프트웨어가 발전함에 따라 빅데이터의 경계가 사라지면서 99%의 시나리오에서는 '빅데이터'가 필요하지 않게 되었다.
이제, 99%의 사용 사례를 독립형 PostgreSQL/DuckDB(및 그 복제본)를 통해 단일 시스템에서 처리할 수 있게 되었다면 전용 분석 도구를 별도로 사용해야 할 이유는 무엇일까? 모든 스마트폰이 자유롭게 문자를 주고받을 수 있다면, 호출기는 무슨 소용이 있을까? (북미 병원에서는 여전히 호출기를 사용한다는 점을 감안하면, '빅데이터'가 진정으로 필요한 시나리오는 1% 미만일 수도 있다.)
근본적인 가정이 바뀌면서 데이터베이스 세계는 다양화 단계에서 다시 융합 단계로, 빅뱅에서 대량 멸종으로 전환되고 있다. 이 과정에서 통합(unified), 다중 모델인(multi-modeled), 초융합(super-converged) 데이터베이스의 새로운 시대가 도래하여 OLTP와 OLAP가 다시 결합할 것이다. 그렇다면, 데이터베이스 분야를 재통합하는 이 기념비적인 작업을 누가 주도하게 될까?
PostgreSQL: 데이터베이스계의 공룡
데이터베이스 영역에는 시계열, 지리공간, 문서, 검색, 그래프, 벡터 데이터베이스, 메시지 큐, 객체 데이터베이스 등 수많은 틈새 시장이 존재한다. PostgreSQL은, 이러한 모든 영역에서 그 존재감을 드러내고 있다.
예를 들어, 지리공간 데이터베이스에서 사실상 표준이 된 PostGIS 확장 기능, 일반적인 시계열 데이터베이스에 대해 새로운 관점을 제시한 TimescaleDB 확장 기능, 전용 벡터 데이터베이스 틈새 시장을 개척한 벡터 확장 기능인 PGVector가 있다.
이러한 현상은 처음이 아니라, 가장 오래되었으면서 가장 큰 하위 도메인인 OLAP 분야에서 다시 관찰되고 있다. 하지만, PostgreSQL의 야망은 OLAP에서 멈추지 않고 전체 데이터베이스 영역을 주시하고 있다.

PostgreSQL의 장점은 무엇일까? 물론 PostgreSQL은 진보된 데이터베이스이며, Oracle 또한 그렇다. 그런데, PostgreSQL은 MySQL과 마찬가지로 오픈 소스이다. PostgreSQL의 장점들은 진보된 형태이면서 오픈소스라는 점에서 비롯되며, 이를 통해 Oracle/MySQL과 경쟁할 수 있다. 그리고, 진정으로 고유한 장점은 PostgreSQL의 확장성이 뛰어나고 확장 기능 생태계가 번창하고 있다는것이다.
뛰어난 확장성의 마법
PostgreSQL은 단순한 관계형 데이터베이스가 아니라 전체 데이터베이스 영역을 아우를 수 있는 데이터 관리 프레임워크이다. PostgreSQL은 오픈 소스이며 진보된 형태라는 점 외에도 확장성, 즉 인프라의 재사용성과 확장 기능을 다양하게 구 구성할 수 있는 가능성에서 경쟁력을 가지고 있다.
PostgreSQL을 사용하면 데이터베이스의 공통 인프라를 활용하여, 최소한의 비용으로 기능을 제공하는 확장 기능을 개발할 수 있다. 예를 들어, 수천 줄의 코드에 불과한 벡터 데이터베이스 확장 프로그램인 PGVector는 수백만 줄에 달하는 PostgreSQL에 비해 매우 적은 복잡성을 가진다. 하지만, 이 작은 규모의 확장 기능은 완벽한 벡터 데이터 유형과 인덱싱 기능을 구현하여 수많은 전문 벡터 데이터베이스보다 뛰어난 성능을 발휘한다.
어떻게 이것이 가능할까? PGVector의 개발자들은 데이터베이스에서 일반적으로 고려되는 추가적인 복잡성에 대해 걱정할 필요가 없었기 때문이다: 수백만 줄의 코드가 필요한 ACID, 복구, 백업 및 PITR(Point In Time Recovery), 고가용성, 액세스 제어, 모니터링, 배포, 타사 생태계 도구, 클라이언트 드라이버 등을 제대로 해결하려면 수백만 줄의 코드가 필요한데, PostgreSQL의 존재로 PGVector 개발자들은 문제의 본질적인 복잡성(벡터 데이터 처리)에만 집중할 수 있다.
예를 들어, ElasticSearch는 Lucene 검색 라이브러리를 기반으로 개발되었으며, Rust 생태계에는 Lucene의 대안으로 개선된 형태의 차세대 전체 텍스트 검색 라이브러리인 Tantivy가 있다. ParadeDB는 이를 래핑(wrapping)하고 PostgreSQL의 인터페이스에 연결하기만 하면 ElasticSearch와 비슷한 검색 서비스를 제공할 수 있다. 이러한 예에서 알 수 있는 중요한 점은, PostgreSQL은 전체 PG 생태계 결합의 힘(예: PGVector를 사용한 하이브리드 검색)을 활용하여 다른 전용 데이터베이스보다 더 유리한 지점에서(unfairly) 경쟁할 수 있다는 것이다.

서로 다른 확장 기능을 함께 사용할 수 있는 '확장 기능 구성 가능성'을 통해 1+1 >> 2 의 시너지 효과를 창출할 수 있다. 예를 들어, TimeScaleDB는 공간-시간(spatial-temporal) 데이터 지원을 위해 PostGIS와 결합할 수 있으며, 전체 텍스트 검색을 위한 BM25 확장 기능은 PGVector 확장 기능과 결합하여 하이브리드 검색 기능을 제공할 수 있다.
또한 분산 확장 기능인 Citus는 독립형 클러스터를 수평적으로 분할된 분산 데이터베이스 클러스터로 투명하게 변환할 수 있다. 이 기능은 다른 기능들과 유기적으로 결합할 수 있어, PostGIS는 분산형 지리공간 데이터베이스로, PGVector는 분산형 벡터 데이터베이스로, ParadeDB는 분산형 전체 텍스트 검색 데이터베이스로 만들 수 있다.
더욱 강력한 점은, 확장 기능들이 번거로운 메인 브랜치 병합이나 조정 없이 독립적으로 발전한다는 점이다. PG의 확장성 덕분에 수많은 팀이 동시에 데이터베이스의 가능성을 탐색할 수 있으며, 모든 확장 기능은 데이터베이스 핵심 기능의 안정성에 영향을 주지 않으면서 선택적으로 작동한다. 성숙하고(mature) 견고한(robust) 기능들만이 메인 브랜치에 안정적으로 병합될 수 있다.
뛰어난 확장성의 마법을 통해 기본적인 안정성과 민첩한 기능을 모두 갖춘 PostgreSQL은 데이터베이스 업계에서 독보적인 존재로 자리매김하며, 데이터베이스 환경의 게임 규칙을 바꾸고 있다.
DB 분야의 게임 체인저
PostgreSQL의 등장으로 데이터베이스 영역의 패러다임이 바뀌었다. 새로운 데이터베이스 커널을 만들기 위해 노력하는 팀들은, 이제 오픈 소스의 풍부한 기능을 갖춘 Postgres와 어떻게 경쟁할 것인가라는 엄청난 시련에 직면해 있다. 그러한 경쟁 팀들이 제시하는 고유한 가치는 무엇일까?
혁신적인 하드웨어 혁신이 일어나기 전까지는, 실용적이고 새로운 범용 데이터베이스 커널이 등장할 가능성은 희박해 보인다. 오픈 소스이며 무료라는 PG의 장점을 고려할 때, 다양한 확장 기능으로 강화된 PG의 전반적인 성능에 필적할 수 있는 단일 데이터베이스는 없다.
어떤 틈새(niche) 데이터베이스 제품이 특정 측면에서 PostgreSQL보다 월등히 뛰어난 성능을 발휘할 수 있다면, 그 자체로 틈새 시장을 개척할 수 있다. 그러나, 일반적으로 PostgreSQL 생태계에서 그 제품에 대한 대체 오픈 소스 확장 프로그램이 나오기까지는 그리 오래 걸리지 않는다. 완전히 새로운 데이터베이스를 개발하는 대신 PG 확장 프로그램을 개발하기로 선택하면, 해당 제품을 따라잡는 데에 엄청난 속도 이점을 얻을 수 있다.
이러한 논리가 유지된다면, PostgreSQL 생태계는 눈덩이처럼 커지면서 장점을 쌓아가 몇 년 안에 서버 OS에서 Linux 커널의 지위를 반영하는 독점이 가능할 것이다. 개발자 설문조사와 데이터베이스 트렌드 보고서에서 이러한 추세를 확인할 수 있다.
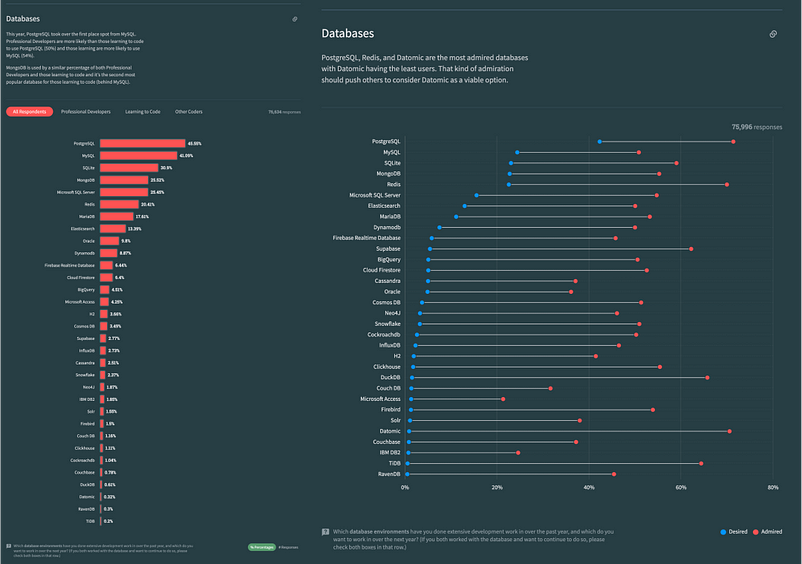
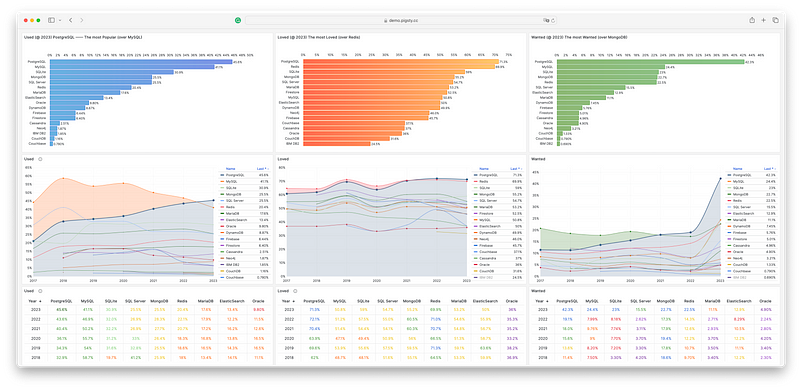
PostgreSQL은 오랫동안 HackerNews와 StackOverflow에서 가장 인기 있는 데이터베이스였다. 많은 신규 오픈소스 프로젝트에서 기본 데이터베이스로 PostgreSQL을 선택하기도 한다. 그리고 많은 신생 기업들도 PostgreSQL에 올인하고 있다.
"Radical Simplicity: Just Use Postgres(극도의 단순성: 그냥 Postgres를 사용하라)"라는 제목에서 알 수 있듯이, 기술 스택을 단순화하고, 구성 요소를 줄이고, 개발을 가속화하고, 위험을 낮추고, 더 많은 기능을 추가하는 것은 단순히 Postgres를 사용함으로써 달성할 수 있다. Postgres는 수백만 명의 사용자에게 손쉽게 서비스를 제공할 수 있는 MySQL, Kafka, RabbitMQ, ElasticSearch, Mongo, Redis를 비롯한 많은 백엔드 기술을 대체할 수 있다. 이제 Postgres 사용은 더 이상 소수의 엘리트 팀에만 국한되지 않고 주류의 모범 사례가 되고 있다.
더 나아가야 할 것들
데이터베이스 도메인의 최종 목표는 예측 가능해보인다. 하지만 우리는 무엇을 할 수 있고, 또 무엇을 해야 할까?
PostgreSQL은 이미 대부분의 시나리오에서 거의 완벽한 데이터베이스 커널이므로 커널의 '병목 현상'이 생긴다는 개념은 어울리지 않는다. 커널 수정을 판매 포인트로 선전하는 PostgreSQL과 MySQL를 포크(Forks)하는 것은 본질적으로 크게 의미가 없다.
이는 오늘날 Linux OS 커널의 상황과 유사하다. 수많은 Linux 배포판이 있음에도 불구하고 모두가 동일한 커널을 선택한다. Linux 커널을 포크하는 것은, 불필요한 어려움을 야기하는 것으로 간주되어 업계에서는 이를 꺼려한다.
따라서 주요한 문제점은 더 이상 데이터베이스 커널 자체가 아니라 데이터베이스 확장과 서비스라는 두 가지 방향이다. 전자는 내부적인 확장성과 관련이 있고, 후자는 외부적인 결합성(composability)과 관련이 있다. OS 생태계와 마찬가지로 경쟁은 데이터베이스 배포판에 집중될 것이다. 데이터베이스 영역에서는, 확장성과 서비스를 중심으로 하는 배포판만이 궁극적으로 성공의 기회를 잡을 수 있다.
커널 레벨의 프로젝트는 여전히 미적지근한 상황이며, 예로 MySQL의 부모(parent) 레벨에서 포크한 MariaDB는 상장 폐지를 앞두고 있다. 반면, 무료 커널을 기반으로 서비스와 확장 기능을 제공하여 수익을 올리는 AWS는 번창하고 있다. 수많은 PG 생태계 확장 및 서비스 배포에 투자가 유입되었다. 예를 들어, Citus, TimescaleDB, Hydra, PostgresML, ParadeDB, FerretDB, StackGres, Aiven, Neon, Supabase, Tembo, PostgresAI, 그리고 자체 PG 배포판인 Pigsty가 있다.
PostgreSQL 생태계의 딜레마는, 많은 확장 기능과 도구가 독립적으로 진화하면서 시너지를 낼 수 있는 통합적인 관리자가 없다는 것이다. 예를 들어, Hydra는 자체 패키지와 Docker 이미지를 출시하고, PostgresML도 각각 자체 확장 기능을 갖춘 PostgreSQL 이미지를 배포하며, 자체 확장 기능만 배포한다. 이러한 이미지와 패키지 배포 방식은 AWS RDS와 같은 통합적인 데이터베이스 서비스와는 거리가 멀다.
AWS와 같은 서비스 제공자와 생태계 통합 시스템조차도, 여러 가지 이유(AGPLv3 라이선스, 멀티테넌시의 보안 문제)로 인해 수많은 확장 기능을 포함하지 못하여 PostgreSQL 생태계 확장 기능의 시너지를 극대화할 수 있는 잠재력을 활용하지 못하고 있다.
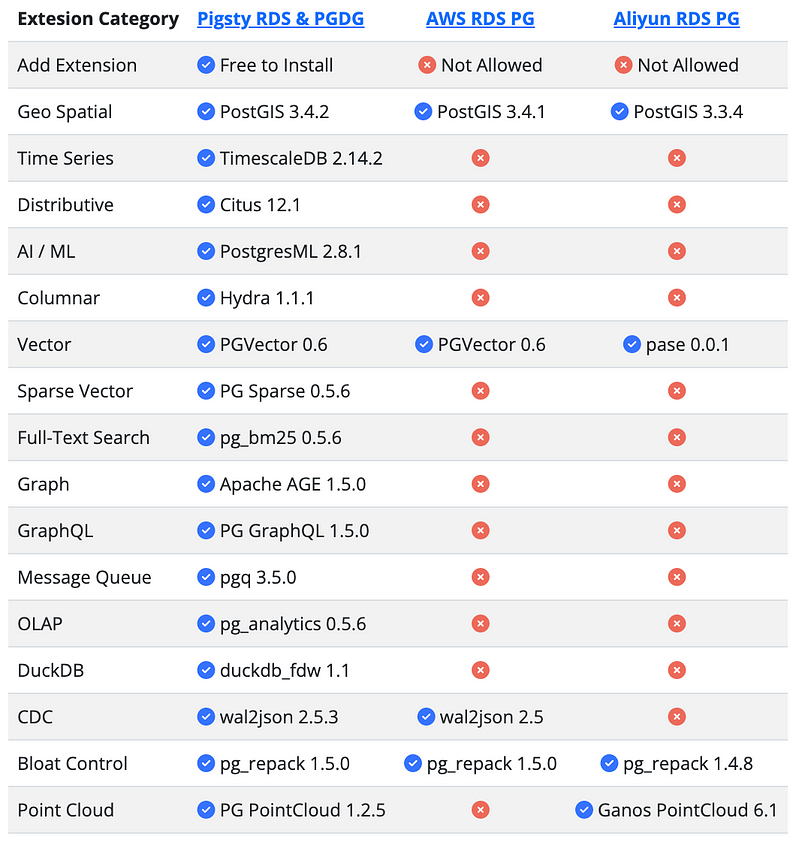
확장 프로그램은 PostgreSQL의 영혼과도 같으며, 확장 기능을 자유롭게 사용할 수 없는 Postgres는 소금 없이 요리를 하는 것과 같다. 이러한 문제들을 해결하는 것이 우리의 주요 목표 중 하나이다.
우리의 해결책: Pigsty
MySQL과 MSSQL을 먼저 접해보았지만, 2015년 PostgreSQL을 처음 사용했을 때 필자는 데이터베이스 영역에서 이 솔루션이 향후 지배적인 위치를 차지할 것이라고 확신했다. 거의 10년이 지난 지금, 필자는 사용자이자 관리자에서 기여자이자 개발자로 전환하여 그 목표를 향한 PG의 행보를 목격하고 있다.
다양한 사용자들과의 상호작용을 통해, 데이터베이스 분야의 단점은 더 이상 다른 커널이 아니라 PostgreSQL만으로도 충분하다는 것을 알게 되었다. 진짜 문제는 커널의 기능을 활용하는 것이며, 이것이 바로 RDS의 성공 비결이다.
하지만 필자는 이 기능이 사이버 상의 권력자*로부터 빌려 쓰는 것이 아니라, 모든 사용자가 사용할 수 있는 무료 소프트웨어처럼 PostgreSQL 커널 자체처럼 접근 가능해야 한다고 생각한다.
*유료 서비스인 AWS의 RDS 서비스를 의미
그래서, 필자는 RDS에 대한 오픈 소스 대안 제품으로 배터리가 포함된(battery-included)* 로컬 우선(local-first)** PostgreSQL 배포판 Pigsty를 만들었으며, 이는 PostgreSQL 생태계를 확장하는 집단적 힘을 활용하고 프로덕션급 데이터베이스 서비스에 대한 액세스를 민주화하는 것을 목표로 한다.
*이 용어는 사용자가 별도로 추가적인 모듈이나 라이브러리를 설치하지 않아도 대부분의 필요한 기능이 이미 포함되어 있다는 의미로 해석된다.
**데이터가 우선적으로 로컬 장치(사용자의 컴퓨터나 모바일 장치 등)에 저장되고 처리되는 데이터베이스를 의미한다. 이러한 방식은 오프라인에서도 데이터베이스가 작동할 수 있게 하며, 네트워크 연결이 복원되었을 때 변경사항을 원격 서버와 동기화할 수 있도록 한다.
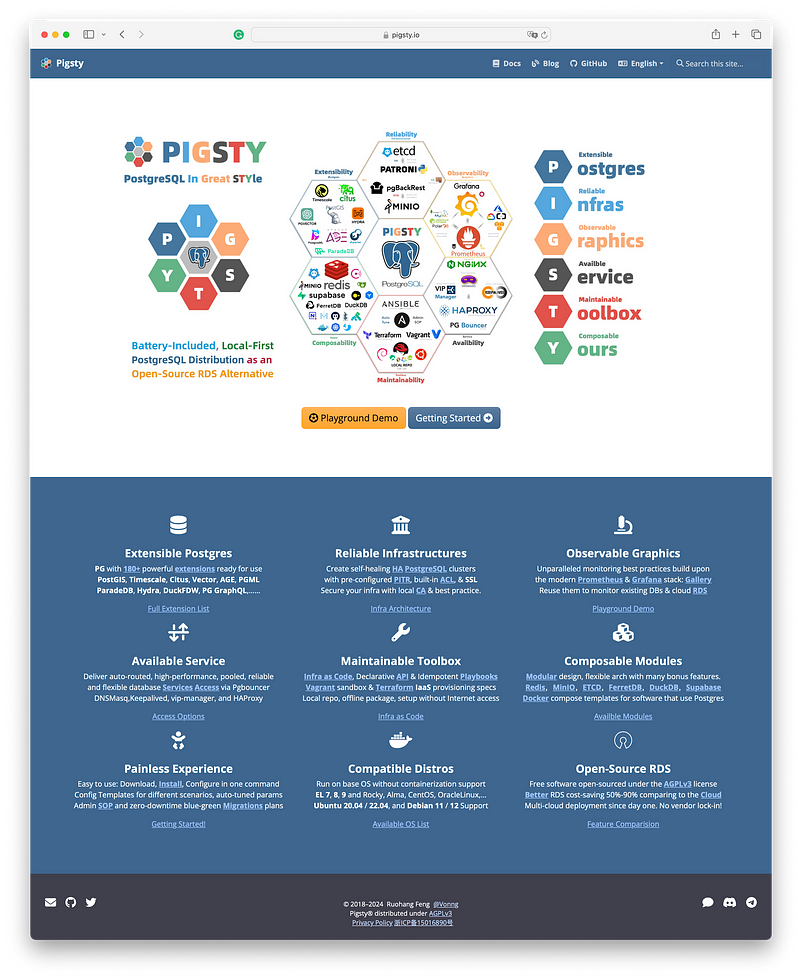
우리는, PostgreSQL 데이터베이스 서비스의 핵심 문제를 다루는 6가지 핵심 명제를 정의했다: 확장 가능한 Postgres, 안정적인 인프라, 관찰 가능한 그래픽(또는 시각화), 사용 가능한 서비스, 유지 관리 가능한 도구 상자(toolbox), 구성 가능한(composable) 모듈.
이러한 가치를 나타낸 이니셜은 Pigsty의 또 다른 약자이기도 하다:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
즉, '당신의 그래픽 Postgres 인프라 서비스 도구 상자'이다.
확장 가능한 PostgreSQL은 이 배포판의 핵심이다. 최근 출시된 Pigsty v2.6에서는 DuckdbFDW와 ParadeDB 확장 기능을 통합하여 PostgreSQL의 분석 기능을 대폭 강화했으며 모든 사용자가 이 기능을 쉽게 활용할 수 있도록 보장한다.
우리의 목표는 데이터베이스계의 우분투와 같은 시너지 효과를 창출하여 PostgreSQL 생태계 내의 강점을 통합하는 것이다. 커널에 대한 논쟁은 일단락되었고, 진정한 경쟁 분야는 여기에 있다고 생각한다.
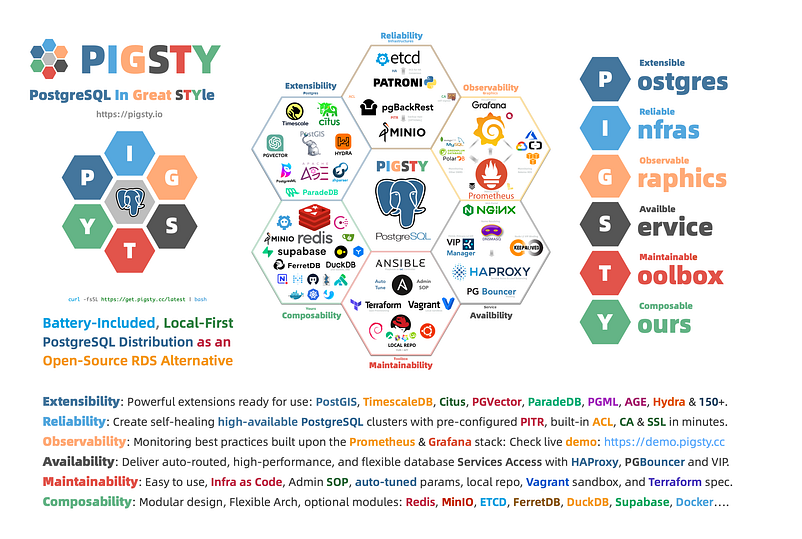
개발자들의 선택에 따라 데이터베이스 세계의 미래가 결정될 것이다. 이 글이 세계에서 가장 진보된 오픈소스 데이터베이스 커널인 PostgreSQL을 더 잘 활용하는 데 도움이 되기를 바란다.
마치며
원문은 Pigsty 서비스에 대한 내용 외에도, Postgres와 그 생태계를 이해하는데 도움이 되는 내용을 포함한다.
이와 함께, 원문 포스트를 공유한 Hacker News의 의견들(Link)을 함께 참고하면 면 좀 더 객관적인 관점으로 Postges 생태계를 바라볼 수 있을 것이다.
'🟡 AIOps' 카테고리의 다른 글
| FastAPI로 복수 파일 업로드 API 구현하기 (1) | 2024.09.06 |
|---|---|
| AWS 클라우드 자격증(SAA-C03) 시험 특징 및 시험 후기 (2) | 2024.04.23 |
| AWS Solutions Architect Associate(SAA-C03) 기출문제 정리 - 04 (0) | 2024.01.03 |
| AWS Solutions Architect Associate(SAA-C03) 기출문제 정리 - 03 (0) | 2023.12.27 |
| AWS Solutions Architect Associate(SAA-C03) 기출문제 정리 - 02 (0) | 2023.12.19 |




댓글