
TL;DR
이번 포스트에서는 벡터 DB 중, pgvector를 이용하여 간단한 RAG 시스템을 구축해봅니다.
pgvector는 PostgreSQL에서 확장 기능(extension)으로 사용할 수 있는 오픈소스 벡터 DB 이며, 오픈소스임에도 불구하고 상용 벡터 DB에 준하는 성능을 보여줍니다.
LangChain 프레임워크 상에서, PDF 파일을 벡터로 변환하여 pgvector에 저장하고 유사 문서를 검색하는 과정까지 수행해보겠습니다.
*샘플 PDF 파일 링크: https://www.dir.ca.gov/injuredworkerguidebook/InjuredWorkerGuidebook.pdf
먼저, 필요한 라이브러리들을 설치해주어야 합니다. LangChain은 LLM 기반 어플리케이션을 구축하는 데에 널리 쓰이는 프레임워크입니다. langchain_postgres와 psycopg는 벡터 DB인 PGVector와의 연동에 이용됩니다. LLMSherpa는 PDF 파일을 전처리할 라이브러리입니다.
pip install langchain
pip install langchain_postgres
pip install "psycopg[binary,pool]"
pip install llmsherpa
이 라이브러리들을 이용해 구현할 RAG 시스템을 간단히 요약하면, 다음 도식과 같습니다.
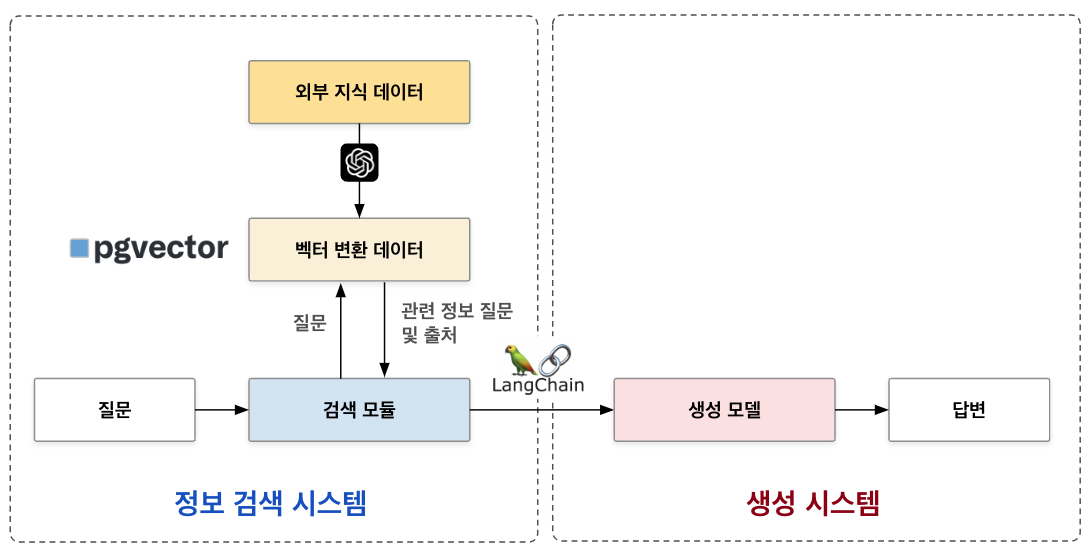
이제 설치한 라이브러리들을 불러옵니다.
import os
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
from langchain.chains import RetrievalQA
from langchain_postgres.vectorstores import PGVector
from langchain.vectorstores.pgvector import DistanceStrategy
from langchain_community.document_loaders.llmsherpa import LLMSherpaFileLoader
from IPython.display import Markdown, display
본 튜토리얼에서는 임베딩 및 챗봇 모델로 OpenAI의 모델을 사용할 것이므로, OpenAI API key를 설정해줍니다. OpenAI key는 OpenAI API Platform에서 결제 수단을 등록하고 발급받을 수 있습니다. os 라이브러리를 이용해 OpenAI key를 설정할 수 있습니다.
챗봇 모델의 temperature 옵션은 모델의 생성 양상을 조정합니다. Temperature 값이 높으면 상대적으로 다양한 종류의 텍스트를 생성하고, temperature 값이 작으면 더 보수적인 양상으로 텍스트를 생성합니다.
os.environ['OPENAI_API_KEY'] = 'YOUR_API_KEY'
embeddings = OpenAIEmbeddings()
chat_llm = ChatOpenAI(temperature = 0.5, model = 'gpt-3.5-turbo-16k')
이제 벡터 DB인 PGVector를 연동해야 하는데, 별도의 DB 서버가 없다면 docker 이미지로부터 pgvector를 실행할 수 있습니다. Docker는 어떤 소프트웨어나 시스템을 실행할 수 있는 환경을 저장해놓은 이미지(image)를 제공하고, 컨테이너(container)에서 이 이미지를 실행하여 간편히 사용할 수 있도록 합니다.
Docker desktop을 시스템 환경에 맞게 설치하고, pgvector를 검색하면 최선 버전을 다운로드(pull)할 수 있습니다.
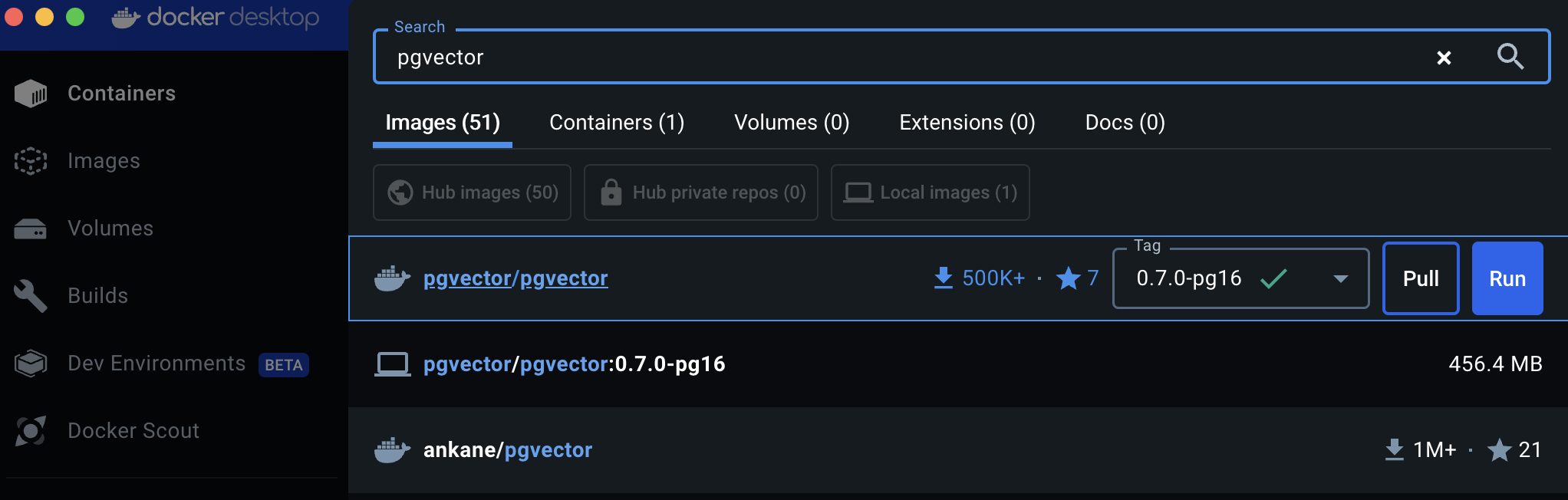
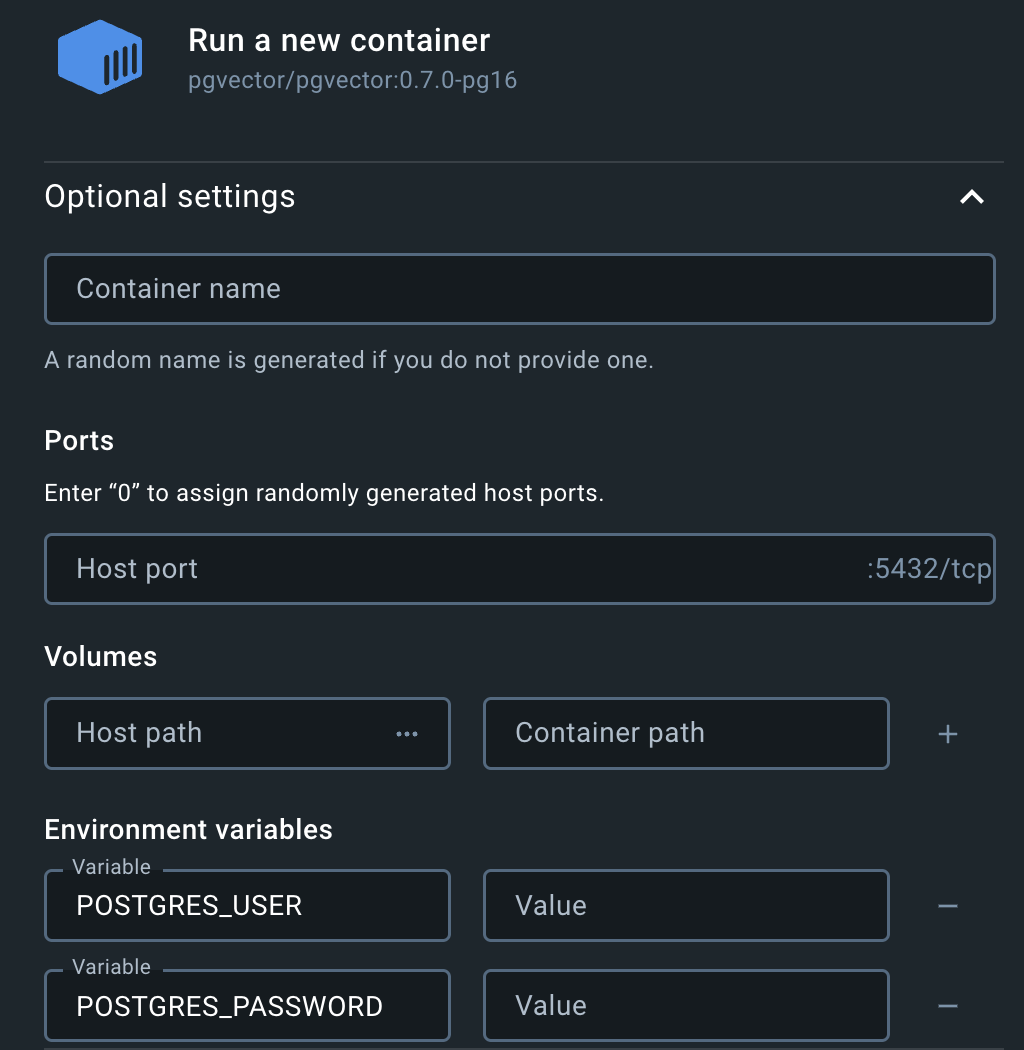
이제 다운받은 이미지를 컨테이너를 통해 실행(Run)하면 되는데, 아마도 비밀번호(POSTGRES_PASSWORD)를 설정하지 않으면 실행할 수 없다는 오류 메시지가 발생할 것입니다. Run을 할 때 표시되는 Optional settings에서 다음과 같이 환경 변수(Enviroment variables)에서 POSTGRES_PASSWORD를 설정해줍니다.
이 외에도 컨테이너 이름(Contatiner name), 호스트 번호(Host port), 데이터베이스 유저 이름(POSTGRES_USER), 데이터베이스 이름(POSTGRES_DB)를 기억하기 쉽게 지정하는 것이 좋습니다.
이제 설정한 DB 연결에 사용할 변수를 입력해줍니다. psycopg에서는 다음과 같은 방식으로 DB 정보를 입력받습니다. 이전 단계에서 설정했던 정보를 입력합니다. 주의할 것은, DB를 로컬에서 실행했을 경우 HOST는 'localhost'로 입력하고 PORT에 Docker에서 Host port로 설정했던 번호를 입력합니다.
connection = 'postgresql+psycopg://DBUSER:DBPW@HOST:PORT/DBNAME
이제 PDF 파일을 전처리할 LLMSherpa 라이브러리를 설정하고, PDF 파일을 전처리합니다. PDF 파일은 포스트 상단에 서술한 주소에서 받을 수 있습니다.
설정 옵션 중 strategy는 'sections'와 'chunks'가 있는데, sections은 챕터나 파트로 문서를 구분하고 chunks는 적당한 길이로 문서를 인위적으로 분절하여 구분합니다. RAG 시스템에는 일반적으로 chunks 방식이 더 적절합니다.
loader = LLMSherpaFileLoader(
file_path="insurance.pdf",
new_indent_parser=True,
apply_ocr=True,
strategy="chunks", # "sections" or "chunks"
llmsherpa_api_url="https://readers.llmsherpa.com/api/document/developer/parseDocument?renderFormat=all",
)
docs = loader.load()
print(len(docs))
이제 벡터 DB인 PGVector를 정의합니다. PDF 파일을 전처리한 docs 변수와 docs 파일을 벡터로 변환할 임베딩 모델 embeddings를 설정합니다. collection_name은 변환된 벡터를 저장할 테이블의 이름이라고 생각하면 됩니다. distance_strategy는 유사도를 검색할 알고리즘을 지정합니다. connection 변수에는 앞서 설정한 DB 정보를 지정합니다.
vectorstore = PGVector.from_documents(
documents = docs,
embedding = embeddings,
collection_name = "insurance",
distance_strategy = DistanceStrategy.COSINE,
use_jsonb = True,
connection=connection
)
이 벡터 DB를 이용하여 검색기(retriever) 변수를 설정합니다. search_kwargs 중 'k'는 입력 쿼리에 대해 검색해 반환할 문서의 수를 지정합니다.
retriever = vectorstore.as_retriever(
search_kwargs={"k": 4}
)
이제 챗봇 모델과 검색기를 결합하여 QA 체인을 생성합니다. 본 튜토리얼에서는 RetrievalQA를 사용하는데, 다양한 체인 모델이 존재하며 목적에 따라 체인을 선택해 사용하면 됩니다. chain_type은 일반적으로 'stuff'를 지정하면 되고 verbose는 쿼리를 실행할 때 안내문을 출력하는 것을 설정합니다.
qa_chain = RetrievalQA.from_chain_type(
llm=chat_llm,
chain_type="stuff",
retriever=retriever,
verbose=True)
이제 질문을 설정하고, 이에 맞는 문서를 잘 검색하는 지 확인해봅시다. PDF 파일에서 다음 파트를 참고하여, 아래와 같은 쿼리를 지정합니다.

query = "What payments do I receive if I’m on TPD?"
이제 쿼리를 실행하고 결과를 확인해봅시다.
response = qa_chain.invoke(query)
display(Markdown(response['result']))

답변의 내용을 잘 보면, 원 PDF 파일에 포함된 내용을 잘 요약하여 설명해주고 있습니다. 예를 들어, TPD라는 상태에 해당하면 손실을 본 임금의 2/3를 받을 수 있다고 말해줍니다. LLM을 이용하면 이렇게 단순히 검색 뿐 아니라 정보를 알기 쉽게 요약해주는 장점이 있습니다.
마치며
PGVector 공식 문서를 보면 벡터 DB를 사용하기 위한 복잡한 쿼리들을 설명하고 있는데, LangChain을 이용하면 이러한 복잡한 과정 없이도 벡터 DB를 간편히 이용할 수 있습니다.
실제 어플리케이션에서는 여러 기능이 더 추가되지만, 기본적인 구조는 이 튜토리얼에서 소개한 내용을 바탕으로 하므로 벡터 DB나 RAG에 대해 어렵게 생각할 필요는 없습니다.
다만, LangChain은 업데이트가 잦은 편이므로 만약 코드의 내용대로 기능이 실행되지 않는다면 오류 메시지나 커뮤니티를 참고하여 수정하면 되겠습니다.
'🟣 AI Study' 카테고리의 다른 글
| 마구잡이 질문에도 강건한 RAG 시스템 만들기: Query Transformation (0) | 2024.07.20 |
|---|---|
| 문서 내 이미지를 함께 활용할 수 있는 멀티모달(Multi-modal) RAG 시스템 만들어보기 (0) | 2024.06.20 |
| Meta, Llama 3 발표: 현존하는 가장 뛰어난 성능의 퍼블릭 LLM (0) | 2024.04.21 |
| LLM이 표(table)를 잘 이해하도록 하자: Chain-of-table: Evolving tables in the reasoning chain for table understanding (2) | 2024.04.07 |
| ChatGPT에 질문을 해도 반응이 없을 경우 해결 방법 (0) | 2024.03.12 |




댓글