
2024.05.13 - [🟣 AI & ML] - 검색증강생성(RAG) - LangChain과 PGVector를 이용한 간단한 RAG 시스템 구축해보기
TL;DR
이전 포스트에서 소개했던 일반적인 RAG 시스템은 문서의 텍스트만을 추출하여, 생성 모델의 답변에 활용합니다.
하지만, 많은 문서에서는 유용한 정보들이 텍스트가 아닌 이미지로 표현되어 있기도 합니다.
이 때, 멀티모달(multi-modal) 모델을 이용하면 자연어로 문서의 이미지에 대한 검색도 수행할 수 있습니다.
이번 포스트에서는 OpenAI의 멀티모달 모델, PGVector, Qdrant DB, LlamaIndex 등의 도구를 활용하여 문서의 텍스트와 이미지에 함께 질의할 수 있는 멀티모달 RAG 시스템을 구축해보겠습니다.
먼저, 아래와 같이 필요한 라이브러리들을 설치해줍니다. 실행 시기에 따라 라이브러리의 버전 업데이트가 필요할 수 있습니다.
huggingface_hub==0.22.2 # Optional(HuggingFace Spaces 배포 시 필요)
gradio==4.36.1
langchain==0.2.3
langchain_core==0.2.5
langchain_openai==0.1.8
langchain_postgres==0.0.6
llama_index==0.10.43
qdrant_client==1.9.1
llama-index-vector-stores-qdrant
llama-index-multi-modal-llms-openai
llama-index-embeddings-clip
git+https://github.com/openai/CLIP.git
이제 설치한 라이브러리들을 불러옵니다.
import gradio as gr
import os
from langchain_openai import OpenAIEmbeddings
from langchain_postgres.vectorstores import PGVector
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_history_aware_retriever
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
import qdrant_client
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.core import SimpleDirectoryReader
from llama_index.core.indices.multi_modal.base import MultiModalVectorStoreIndex
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
RAG 시스템에 사용할 언어모델 및 멀티모달 모델을 불러옵니다. 구현할 시스템에는 총 4개의 모델이 필요합니다.
- 문서의 텍스트 및 질의를 벡터로 임베딩하는 텍스트 임베딩 모델(OpenAIEmbedding)
- 질의와 검색된 문서를 바탕으로 답변을 생성하는 대화형 언어 모델(ChatOpenAI)
- 이미지를 벡터로 변환하는 모델(OpenAI CLIP)
- 텍스트 질의에 해당하는 이미지를 검색할 수 있는 Text-to-Image 멀티모달 모델(OpenAIMultiModal)
여기서, 1, 2, 4번 모델은 아래와 같이 모델 객체를 정의합니다. 3번의 이미지 임베딩 모델은 이미지 저장소 설정 시 자동으로 할당됩니다.
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
chat_llm = ChatOpenAI(temperature = 0.5, model = 'gpt-4o')
openai_mm_llm = OpenAIMultiModal(model="gpt-4-vision-preview", max_new_tokens=1500)
이제 텍스트 및 이미지 저장소를 설정해줍니다.
- 문서의 텍스트는 OpenAIEmbedding으로 벡터로 변환한 후 PGVector에 저장하고, 이미지는 OpenAI CLIP 모델로 벡터 변환하여 Qdrant DB에 저장할 것입니다.
- PGVector 연결에 필요한 정보들을 connection string으로 구성하여, 이후 PGVector 객체에 입력해줄 것입니다.
- 예제에서 사용한 PGVector는 EC2 인스턴스에서 실행되고 있습니다. Qdrant DB는 별도의 인스턴스 생성 없이 로컬에서도 실행할 수 있습니다.
pg_password = os.getenv("PG_PASSWORD")
aws_ec2_ip = os.getenv("AWS_EC2_IP")
pg_connection = f"postgresql+psycopg://postgres:{pg_password}@{aws_ec2_ip}:5432/postgres"
qd_client = qdrant_client.QdrantClient(path="qdrant_db")
image_store = QdrantVectorStore(client=qd_client, collection_name="image_collection")
storage_context = StorageContext.from_defaults(image_store=image_store)
다음은 프롬프트 설정입니다. 프롬프트는 크게 2종류로 구성됩니다.
- 대화 기록과 현재 질문을 조합하여 요약하는 프롬프트: 이는 챗봇이 계속 지난 대화 내용을 기억하여 일관된 맥락의 답변을 유지할 있도록 합니다. 요약된 대화 기록과 질문은 다시 언어 모델에 입력되어, 최종 답변 생성에 이용됩니다.
- 질문과 대화 기록, 검색 데이터를 바탕으로 최종 답변을 생성하는 프롬프트
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
context: {context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(chat_llm, qa_prompt)
이제 RAG 기능 구현에 필요한 함수들을 차례로 구성할 차례입니다. RAG 시스템에 함수들을 차례로 정의한 뒤, Gradio 인터페이스에서 이 기능을 통합하여 demo를 구성할 것입니다. 먼저 문서의 텍스트로부터 답변을 생성하는 response 함수입니다. response 함수 내에 포함된 주요 기능은 다음과 같습니다.
- response 함수는 Gradio의 챗봇 인터페이스(ChatInterface) 상호작용합니다. 따라서 기본적으로 설정되어 있는 템플릿을 따르며, message(사용자 기록), history(대화 기록)와 같은 변수가 포함됩니다.
- 다만, 우리는 대회 기록을 chat_history라는 별도 변수로 별도로 설정할 것이므로 history 변수는 사용하지 않습니다.
- 사용자가 선택한 문서 이름(doc_label)에 해당하는 벡터 저장소를 지정하고, 해당 문서에 대해 검색을 수행합니다.
def response(message, history, doc_label):
text_store = PGVector(collection_name=doc_label,
embeddings=embeddings,
connection=pg_connection)
retriever = text_store.as_retriever()
history_aware_retriever = create_history_aware_retriever(chat_llm,
retriever,
contextualize_q_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
response = rag_chain.invoke({"input": message, "chat_history": chat_history})
chat_history.extend([HumanMessage(content=message), response["answer"]])
return response["answer"]
다음은 이미지를 검색해오는 img_retrieve 함수입니다.
- 사용자가 지정한 문서(doc_label)에 해당하는 이미지 저장소를 연결하여, 사용자 질문에 대한 이미지를 검색합니다.
- LlamaIndex의 MultiModalVectorStoreIndex에는 이미지를 변환한 벡터 저장소를 지정할 수 있습니다.
- PDF의 이미지는 사전에 추출되어 문서의 이름으로 설정된 폴더에 저장되어 있고, 이를 SimpleDirectoryReader로 불러옵니다. 이미지 벡터 검색 후, 최종적으로 벡터에 해당하는 이미지를 반환하게 됩니다.
- PDF로부터를 이미지 추출하는 방법은 다양한데, 이미지 추출 코드 예시를 아래 링크에서 확인할 수 있습니다.
- https://huggingface.co/spaces/ztor2/multimodal_rag_chat/blob/main/extract_imgs.ipynb
- img_similarity_top_k 옵션은 검색할 이미지의 수를 지정합니다. 여기서는 가장 유사한 3개의 이미지를 검색하도록 설정해봅시다.
def img_retrieve(query, doc_label):
doc_imgs = SimpleDirectoryReader(f"./{doc_label}").load_data()
index = MultiModalVectorStoreIndex.from_documents(doc_imgs,
storage_context=storage_context)
img_query_engine = index.as_query_engine(llm=openai_mm_llm,
image_similarity_top_k=3)
response_mm = img_query_engine.query(query)
retrieved_imgs = [n.metadata["file_path"] for n in response_mm.metadata["image_nodes"]]
return retrieved_imgs
이제 Gradio 모듈을 이용하여, demo 화면을 구성해줍니다. Gradio를 이용하면 복잡한 JavaScript 문법이나 API 설정 없이도, 단일 Python 파일만으로 간편히 demo를 구성할 수 있습니다.
- Blocks나 Row, Column 모듈을 배치하여 화면 레이아웃을 설정합니다.
- Dropdown 모듈로 문서 종류를 입력받습니다. 본 튜토리얼에서는 'LLaVA'라는 AI 논문 문서와, 'Interior'라는 인테리어 카탈로그 문서를 사전에 전처리하여 저장해놓았습니다. 각 문서를 확인할 수 있는 링크는 아래와 같습니다.
- ChatInterface 모듈을 챗봇 기능을 구현합니다.
- Gallery 모듈은 질의에 해당하는 이미지 검색을 수행하면, 검색된 이미지를 보여주는 역할을 합니다.
- Textbox와 Button 모듈로 이미지 검색 질의 입력단을 구성합니다.
with gr.Blocks(theme=gr.themes.Monochrome()) as demo:
with gr.Row():
gr.Markdown(
"""
# 🎨 Multi-modal RAG Chatbot
""")
with gr.Row():
gr.Markdown("""Select document from the menu, and interact with the text and images in the document.
- Sample documents: [LLaVA paper](https://arxiv.org/pdf/2304.08485), [Interior design catalog](https://www.designblendz.com/hubfs/206.00%20Virtual%20Staging/206.00_VirtualStagingCatalog_SS17_Pages.pdf)
""")
with gr.Row():
with gr.Column(scale=2):
doc_label = gr.Dropdown(["LLaVA", "Interior"], label="Select a document:", value="Interior")
chatbot = gr.ChatInterface(fn=response, additional_inputs=[doc_label], fill_height=True)
with gr.Column(scale=1):
sample_1 = "https://i.pinimg.com/originals/e3/44/d7/e344d7631cd515edd36cc6930deaedec.jpg"
sample_2 = "https://www.explore.co.uk/medialibraries/explore/blog-images/2018%2012%20december/shutterstock_1080525158-2.jpg?ext=.jpg&width=620&format=webp&quality=80&v=202103231018"
sample_3 = "https://media.istockphoto.com/id/495292220/photo/colorful-cute-toucan-tropical-bird-in-brazilian-amazon-blurred-background.webp?b=1&s=170667a&w=0&k=20&c=9uiwllVE4BPs9Ia8SQOhwqfcPJ6ajYZcmnxCRbktR4k="
gallery = gr.Gallery(label="Retrieved images",
show_label=True, preview=True,
object_fit="contain",
value=[(sample_1, 'sample image 1'),
(sample_2, 'sample image 2'),
(sample_3, 'sample image 3')])
query = gr.Textbox(label="Enter query", value="Show images of nautica decor.")
button = gr.Button(value="Retrieve images")
button.click(img_retrieve, [query, doc_label], gallery)
demo.launch()
실행한 demo 화면은 다음과 같습니다.
- Select a document에서 정보를 검색할 문서를 선택합니다.
- 좌측 하단에서 문서의 텍스트에 대한 질의를 수행하여, 언어 모델을 통한 답변을 얻을 수 있습니다.
- 우측에서는 문서의 이미지에 대한 질의를 수행하여, 멀티모달 모델을 통한 이미지 검색 결과를 볼 수 있습니다.
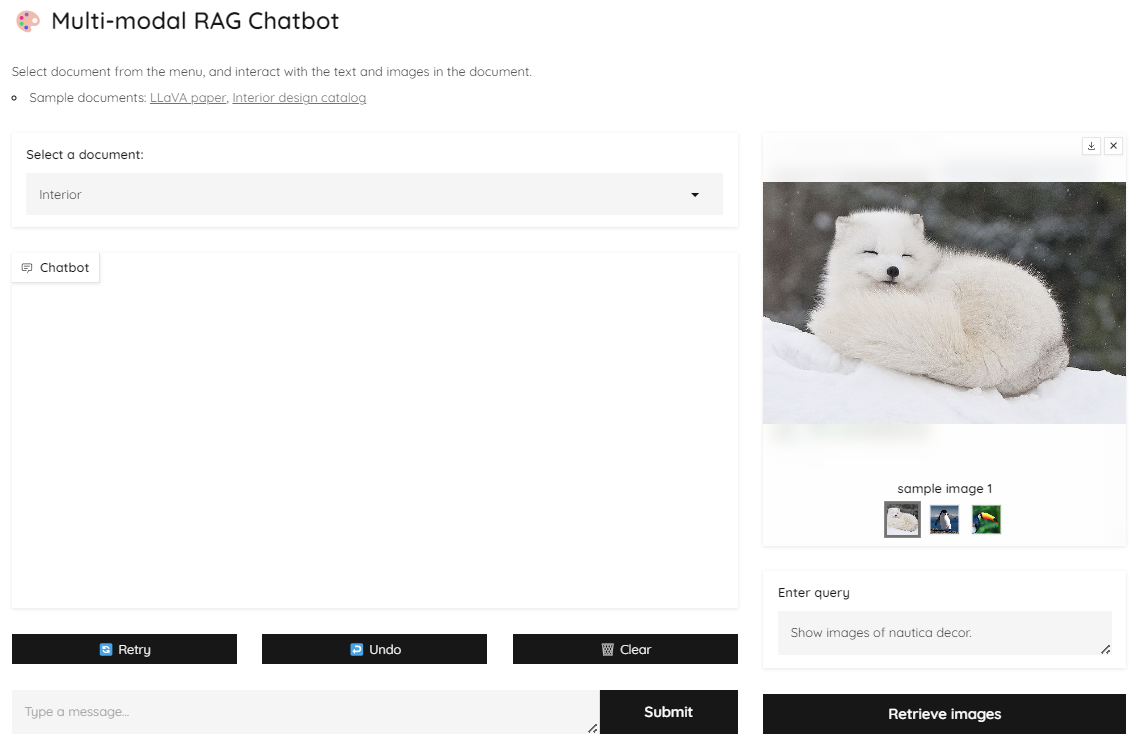
한 번 질의를 수행해봅시다. Interior 문서에 포함된 'nautica decor' 라는 키워드에 대한 텍스트 정보와 이미지 정보를 함께 검색하고 싶습니다.
- Interior 문서를 선택합니다.
- 좌측의 챗봇에 'What is nautica decor?'라는 질의를 입력하고 Submit 버튼을 클릭하면, 문서에 포함된 nautica decor에 대한 텍스트 정보가 요약되어 답변으로 출력됩니다.
- 우측의 이미지 검색 모듈에 'Show images of nautica decor.'라는 질의를 입력하면, nautica decor에 대한 이미지가 잘 출력되는 것을 확인할 수 있습니다.'

마치며
이번 포스트에서는, 문서 내의 텍스트와 이미지를 함께 활용하여 검색이 가능한 멀티모달 RAG를 구현해보았습니다.
최근 GPT-4o가 발표되면서 단순히 텍스트만이 아닌 이미지, 음성, 영상 등을 함께 활용하는 생성 모델이 주목을 받고 있습니다.
다만, LangChain과 LlamaIndex와 같은 AI 프레임워크에서 사용할 수 있는 멀티모달 관련 모듈은 아직 초기 단계이므로 사용성이나 다양성, 완성도 면에서 보완이 필요합니다.
본 튜토리얼을 참고하여, 각자 본인만의 효과적인 멀티모달 시스템을 구상해보면=아도 좋을 것 같습니다.
'🟣 AI Study' 카테고리의 다른 글
| 405B 사이즈 모델을 포함한 Llama 3.1 버전 릴리즈 노트 살펴보기 (0) | 2024.07.25 |
|---|---|
| 마구잡이 질문에도 강건한 RAG 시스템 만들기: Query Transformation (0) | 2024.07.20 |
| 검색증강생성(RAG) - LangChain과 PGVector를 이용한 간단한 RAG 시스템 구축해보기 (0) | 2024.05.13 |
| Meta, Llama 3 발표: 현존하는 가장 뛰어난 성능의 퍼블릭 LLM (0) | 2024.04.21 |
| LLM이 표(table)를 잘 이해하도록 하자: Chain-of-table: Evolving tables in the reasoning chain for table understanding (2) | 2024.04.07 |




댓글