

Runway는 대표적인 AI 기반 영상 생성 서비스 중 하나입니다. OpenAI의 Sora는 아직 일반 사용자가 이용할 수 없으며, 어느 정도 퀄리티를 보장할 수 있는 영상 생성 서비스는 Runway와 Luma AI 정도인 것 같습니다. Runway는 현재 Gen-3 Alpha 와 Gen-3 Alpha Turbo 모델이 플래그십 모델이며, 웹 서비스 또는 API로 이용할 수 있습니다. Luma AI는 Dream Machine 이라는 모델을 결제 후 API로 이용할 수 있습니다.
Runway 홈페이지
Luma 홈페이지
Runway는 결제를 하지 않아도, 약 120크레딧의 일회성 무료 크레딧을 기본 제공합니다. 영상 하나당 50 - 100 크레딧 정도가 소모되므로 체험정도만 할 수 있겠습니다.
본 포스트에서는 Runway의 유료 플랜 중 Standard 버전을 결제해보고, 여러 가지 설정을 통해 결과가 어떻게 나오는 지 확인해보겠습니다. 유료 플랜은 Basic 부터 Enterprise까지 있으며, 각 플랜은 모델 종류, 등급에 따른 사용 가능 여부나 영상 생성 길이, 크레딧 수에서 차이가 있습니다.
Runway 유료 플랜 요금제 비교 페이지
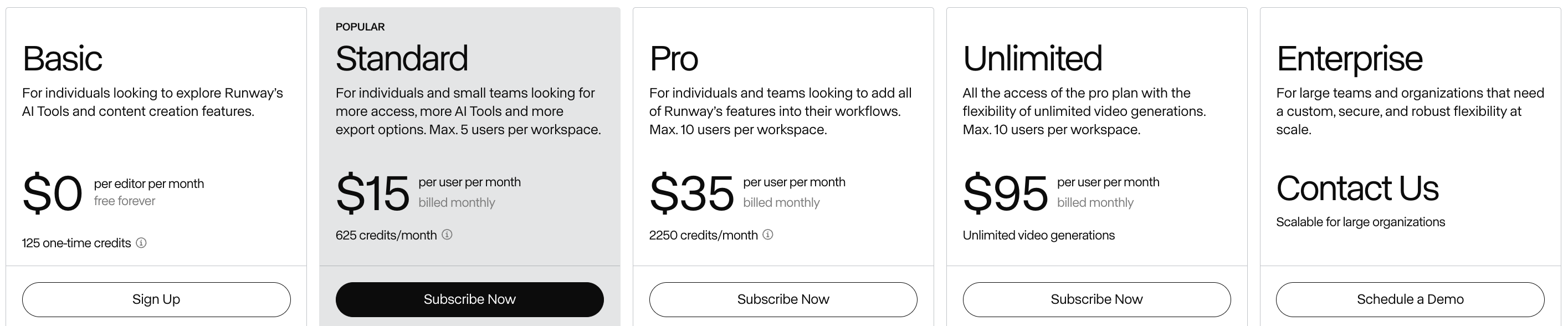
Standard 버전은 15달러, 한화 약 2만원이며 월 625 크레딧을 제공합니다. 연 단위 결제는 조금 더 할인이 됩니다. 저는 결제를 하니 1025 크레딧이 들어와 있던데 왜 더 많이 들어왔는지는? 잘 모르겠습니다. 어쨌든 고맙게 잘 사용해보겠습니다. 생성 서비스별 크레딧 소모량은 다음과 같습니다.

아래에서 확인하겠지만 플래그십 모델인 Gen-3 Alpha 모델을 사용한다면 영상은 5초 또는 10초 생성이 가능합니다. 10초 영상 하나에 100 크레딧이 소모되겠군요. Standard 버전의 크레딧이 그리 넉넉한 양은 아닙니다. 우선 대시보드에 진입해보겠습니다.
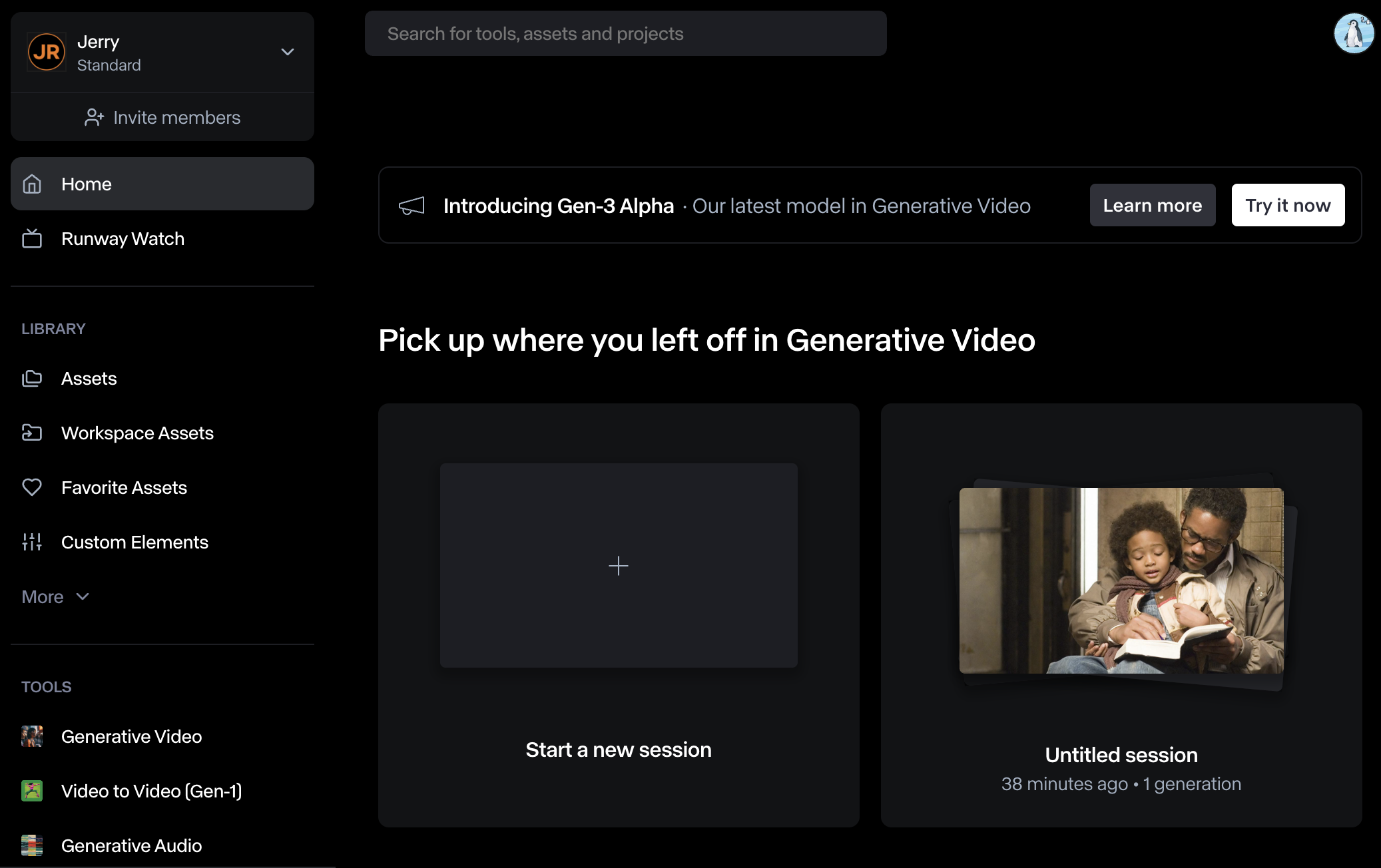
좌측 사이드바를 살펴보면, Runway Watch는 다른 이용자가 생성한 영상을 감상할 수 있는 메뉴입니다. Library는 업로드하거나 생성한 영상 파일들을 관리하는 탭입니다. Tools 탭에서는 생성 서비스를 기준으로 세션을 시작할 수 있습니다. 중앙의 Start a new session을 클릭하여 세션을 시작할 수 있습니다.
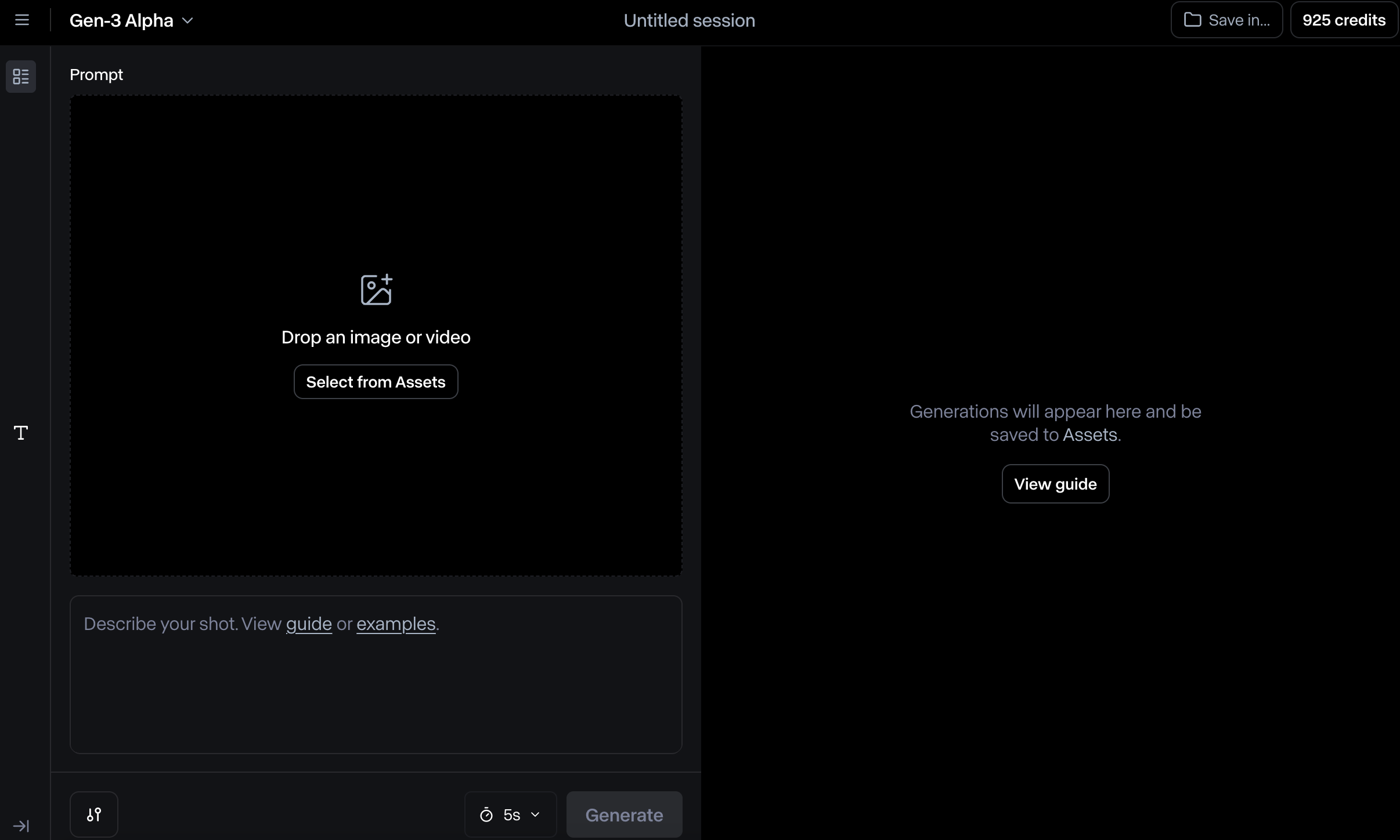
좌측 화면에서는 이미지를 업로드할 수 있고, 프롬프트와 영상 길이를 설정할 수 있습니다. 좌측 상단에서 생성 모델을 선택할 수 있습니다. 가장 좌측 하단의 equalizer같은 아이콘을 클릭하면 세부 설정을 할 수 있습니다.
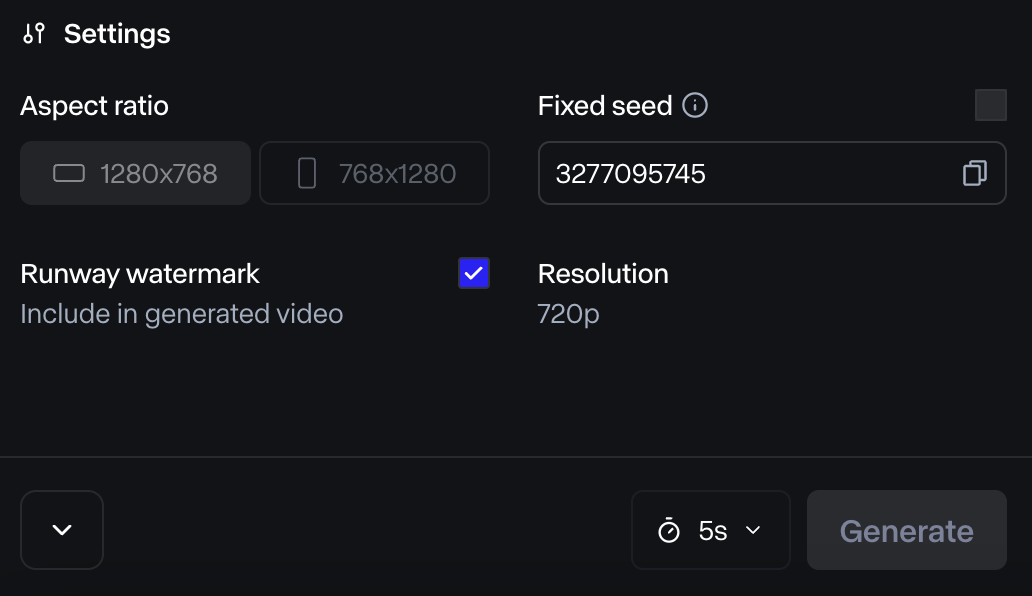
입력하는 이미지나 영상의 비율은 1280x768 또는 768x1280 으로 맞추어야 합니다. 미리 맞추어 업로드할 필요는 없고, 업로드를 하면 crop할 수 있습니다. Seed를 설정하면 같은 seed 값을 가지고 생성된 이미지는 유사한 양상을 보이게 됩니다. 유사한 스타일의 이미지를 여러 개 재현하고 싶을 때 사용하는 옵션입니다. Watermark는 우측 하단의 Runway 로고 삽입 여부이고, Resolution은 720p로 고정되어 있습니다.
먼저, 요즘 인기인 넷플릭스의 ‘흑백요리사’ 프로그램에서 백종원 님이 음식을 심사하는 사진을 입력하여 5초 길이의 영상을 제작해봅시다. 프롬프트는 'A blindfolded man happily eats food fed to him by another man.(눈을 가린 남자가 다른 남자가 먹여주는 음식을 즐겁게 먹고 있다.)'로 입력해봅니다. Runway의 모델의 프롬프트는 다국어를 지원하지 않으므로 영어로 입력해주어야 합니다.

Generate를 누르면 영상 생성이 시작됩니다.
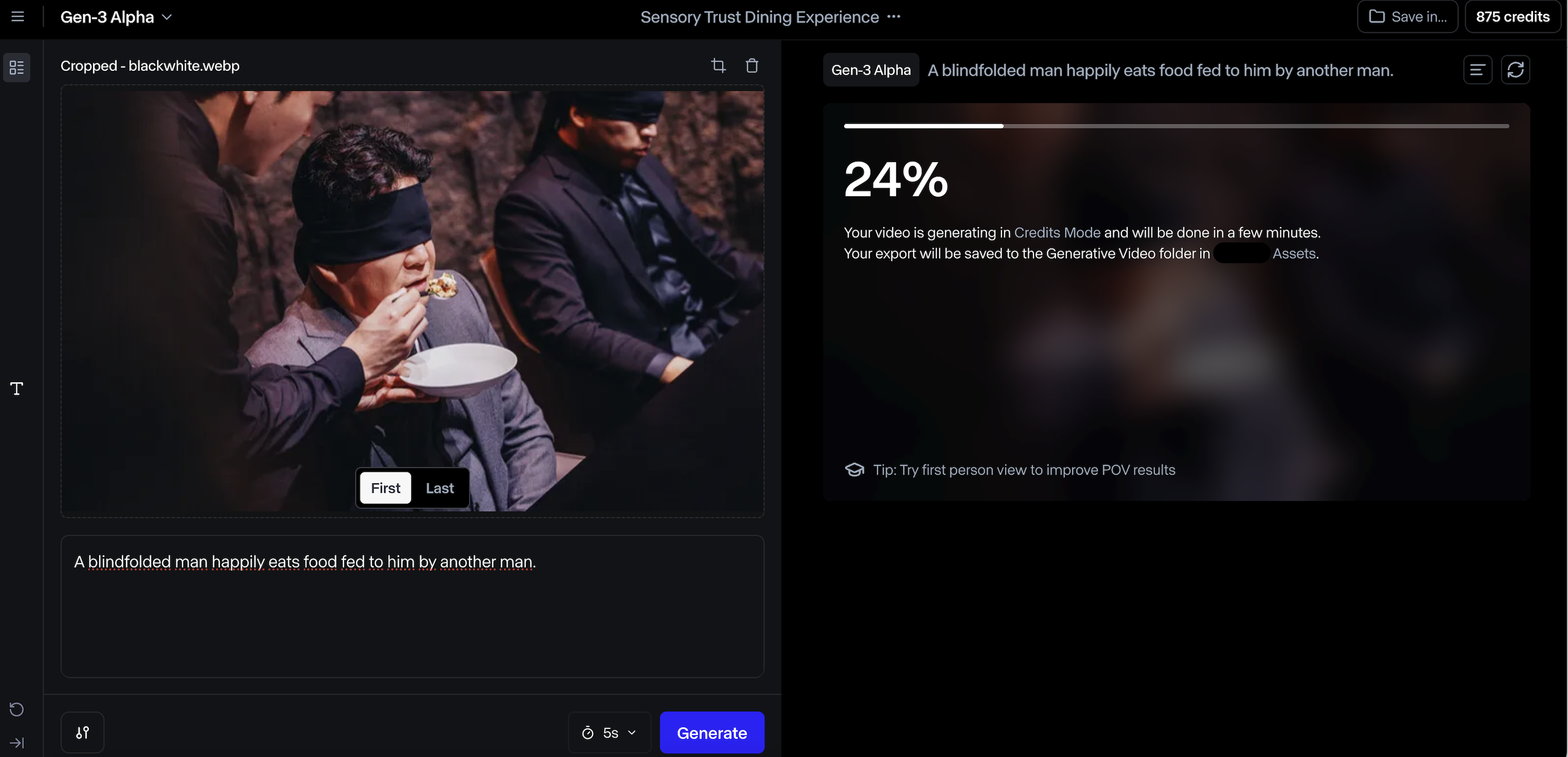
생성된 영상은 대시보드의 Workspace에도 저장되고, 다운받을 수도 있습니다. 생성 결과를 확인해봅시다.
플래그십 모델을 사용했는데도 약간은 당황스러운 결과물이 나왔습니다. 무언가 먹는 표현은 잘 되었으나, 먹는 주체에 대한 가이드가 명확히 모델에 이해가 되지 않은 것 같아 여러 인물이 먹는 제스처를 취하고 있습니다. 아마도 화면에 여러 객체가 포함되어 있어, 약간은 어려운 입력이 아니었나 싶습니다.
이번엔 조금 쉬워보이는 이미지를 이용하고, 생성 품질 향상을 위해 Gen-3 모델 프롬프트 가이드를 참고해봅시다. 다음은 입력 이미지를 사용하는 경우의 프롬프트 가이드입니다.
When using input images, focus on describing the movement you'd like in the output, rather than the contents of the image.
(입력 이미지를 사용할 때는 이미지의 내용보다는 출력물에 원하는 동작을 설명하는 데 집중하세요.)
In example, you might try the following prompt if using an input image that features a character:
(예를 들어, 입력 이미지를 사용하는 경우 다음 프롬프트를 시도해 볼 수 있습니다:)
Subject cheerfully poses, her hands forming a peace sign.
프롬프트 가이드를 따라 인물의 동작에 집중하여 다음과 같은 영화 이미지에, 'The man on the motorbike on the right is jumping towards the left.(오른쪽의 오토바이를 탄 남자가 왼쪽으로 점프한다.)' 라는 동작을 표현하는 프롬프트를 함께 입력해봅시다.

아래는 생성 결과입니다.
뭔가 왼쪽보다는 너무 위로 날아가는 느낌이긴 하지만, 그래도 꽤나 자연스러운 영상이 나왔습니다. 아직은 기능이 제한적이고 종종 아래와 같은 상당히 당혹스러운 결과를 출력하기 때문에, 비즈니스 목적으로 사용하는 것은 개인적으로 선뜻 추천하기는 어려울 것 같습니다. 다만, 프롬프트를 잘 조정한다면 목적에 따라 창의적인 영상을 제작하는 데에 쓰임새가 있을 것 같습니다.
'🟣 AI Study' 카테고리의 다른 글
| 아이폰의 애플 인텔리전스는 어떻게 학습되었을까? Apple Foundation Model(AFM) 논문 살펴보기 - 02 (2) | 2024.12.29 |
|---|---|
| 아이폰의 애플 인텔리전스는 어떻게 학습되었을까? Apple Foundation Model(AFM) 논문 살펴보기 - 01 (2) | 2024.11.17 |
| 규모 대비 성능을 크게 높인 Ai2의 오픈소스 거대 멀티모달 모델(LMM) Molmo 살펴보기 (3) | 2024.10.01 |
| Phi-3.5와 PGVector 벡터 DB를 이용한 검색증강생성(RAG) 시스템 구축하기 (2) | 2024.09.26 |
| Meta, Llama 3.2 출시: 경량 모델(1B, 3B)과 비전(Vision) 모델 공개 (3) | 2024.09.26 |




댓글