

TL;DR
앨런(Allen) AI 연구소와 워싱턴대가 협력하여 구축한 Ai2의 멀티모달 모델군 Molmo와 데이터셋 Pixmo가 공개되었습니다. 자체 구축한 고품질 데이터셋을 활용해 모델 크기 대비 성능을 크게 높였고, 대화형 모델에 맞게 평가 방법을 개선하여 체계적인 검증을 수행한 점이 눈에 띕니다. 무엇보다, 데이터셋을 공개한다는 것이 연구자들에게는 반갑습니다. 이번 포스트에서는 Molmo의 논문 및 블로그를 참고하여 모델 구조와 훈련 방법, 검증 결과를 간단히 살펴보겠습니다.
원문 및 데모 링크: https://molmo.allenai.org
논문 링크: https://arxiv.org/abs/2409.17146
Molmo And Pixmo: Open Weights And Open Data For State-Of-The-Art Multimodal Models
Molmo와 Pixmo: 최첨단(SOTA) 멀티모달 모델을 위한 개방형 가중치 및 개방형 데이터
요약
- 현재 최고 수준 멀티모달 모델은 대부분 비공개임.
- 공개 가중치를 사용하는 고성능 모델들은 대부분 기존의 비공개 비전 언어 모델(VLM)에서 생성된 합성 데이터를 사용해 성능을 향상시킴.
- 이에 따라 VLM을 바닥 단계부터 구축하는 방법에 대한 기초 지식이 부족함.
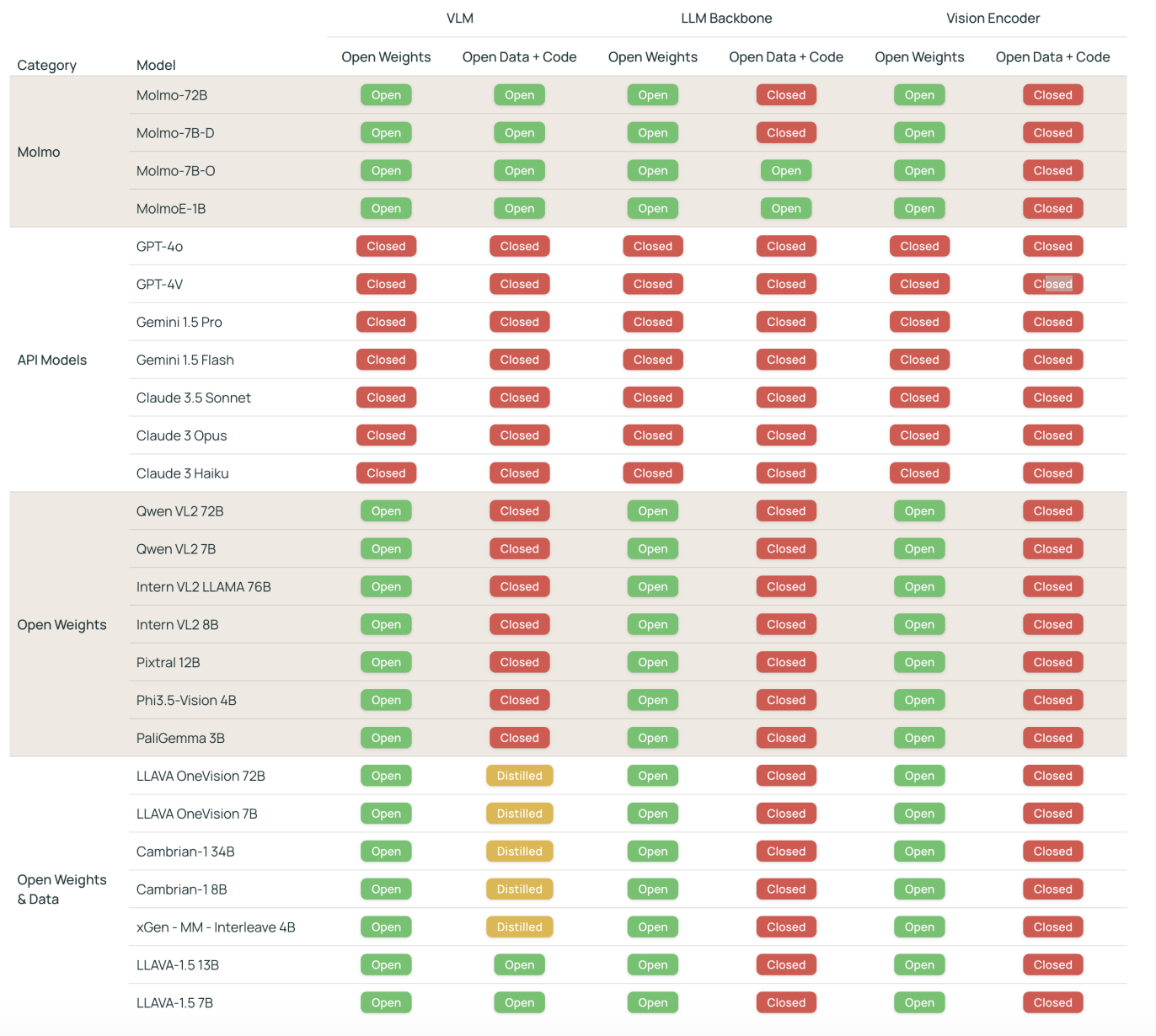
- Molmo는 완전히 공개되면서 최고 수준의 성능을 자랑하는 새로운 VLM 모델군을 제시함.
- 주요 혁신 요소는 음성 기반 설명을 사용해 사람이 직접 수집한 세밀한 이미지 캡션 데이터셋임.
- 사용자의 다양한 상호작용을 가능하게 하기 위해 자연 질문과 답변 데이터 및 2D 포인팅 데이터를 포함한 다양한 데이터셋으로 파인튜닝함.
- 모델 아키텍처, 훈련 파이프라인, 그리고 새로운 데이터셋의 품질이 Molmo의 성공에 중요한 요소임.
- 72B 파라미터 모델은 공개된 모델 및 데이터 범주에서 최고 수준일 뿐만 아니라 GPT-4o, Claude 3.5, Gemini 1.5와 같은 비공개 시스템과도 비교 가능한 성능을 보임.
- 모델 가중치, 캡션 및 파인튜닝 데이터, 소스 코드를 곧 공개할 예정이며, 일부 모델 가중치와 추론 코드, 데모는 이미 공개됨.
Molmo 소개 및 개발 배경
멀티모달 모델의 발전
텍스트와 이미지를 모두 처리할 수 있는 대형 언어 모델(LLM)의 확장은 복잡한 시각적 질문에 답하거나 이미지 설명을 생성하는 등의 멀티모달 기능을 크게 향상시킴. 그러나 성능이 뛰어난 비전-언어 모델(VLM)은 대부분 비공개 상태로, 모델 가중치, 데이터, 코드가 공개되지 않음.
오픈 모델 개발 시도
과학적 탐구를 촉진하기 위해 LLaVA와 같은 초기 연구들이 공개 가중치와 데이터를 제공하며 오픈 VLM을 개발했으나, 현재는 최신 기술에 뒤처짐. 최근의 더 강력한 오픈 모델들은 대부분 합성 데이터를 사용하거나 비공개 시스템에 의존하는 경우가 많아, 비공개 모델을 단순히 '증류(distillation)'하는 결과를 초래함.
Molmo 소개
Molmo는 공개된 가중치와 비전-언어 학습 데이터를 제공하는 새로운 VLM 모델군으로, 다른 VLM이나 비공개 시스템의 합성 데이터에 의존하지 않음. 독립적으로 사전 학습된 비전 인코더와 언어 모델을 연결해 새로운 데이터셋으로 훈련하며, 이후 지시를 따르는 모델로 파인튜닝함.
간소화된 학습 과정
기존의 오픈 VLM들은 모델 일부를 고정(freeze)하거나 대규모의 약하게 연결된* 이미지-텍스트 데이터로 학습하는 반면, Molmo는 높은 품질의 데이터에 의존하며 복잡한 사전 학습 단계를 생략함. 이 모델의 성공은 아키텍처 설계, 학습 파이프라인, 그리고 새로 수집한 PixMo 데이터셋의 품질에 기인함.
*텍스트가 이미지를 명확히 표현하지 못하는 것을 일컫는 것으로 해석됨.
데이터 수집 전략
기존의 인간 주석 작성자에게 이미지 설명을 작성하게 하는 방법은 경제적이지 않으며 주로 눈에 띄는 요소들만 언급되고, 비공개 모델의 출력을 복사해 붙여넣는 문제도 발생함. Molmo는 이러한 문제를 해결하기 위해 주석 작성자들에게 음성으로 이미지를 묘사하게 함으로써 더 빠르고 상세한 설명을 얻음.
파인튜닝 데이터
Molmo 모델은 표준 학술 데이터셋과 함께 다양한 새로운 데이터로 미세조정됨. 이 데이터에는 사용자들이 실제로 물어볼 법한 질문들, 문서 기반 질문-답변 데이터, 아날로그 시계 읽기 데이터, 그리고 2D 포인팅 데이터를 포함함. 포인팅 데이터는 모델이 시각적으로 특정 요소를 지목할 수 있게 하여, 더 자연스러운 답변을 가능하게 하고 정확한 개수 세기 등을 향상시킴.
모델 성능 평가
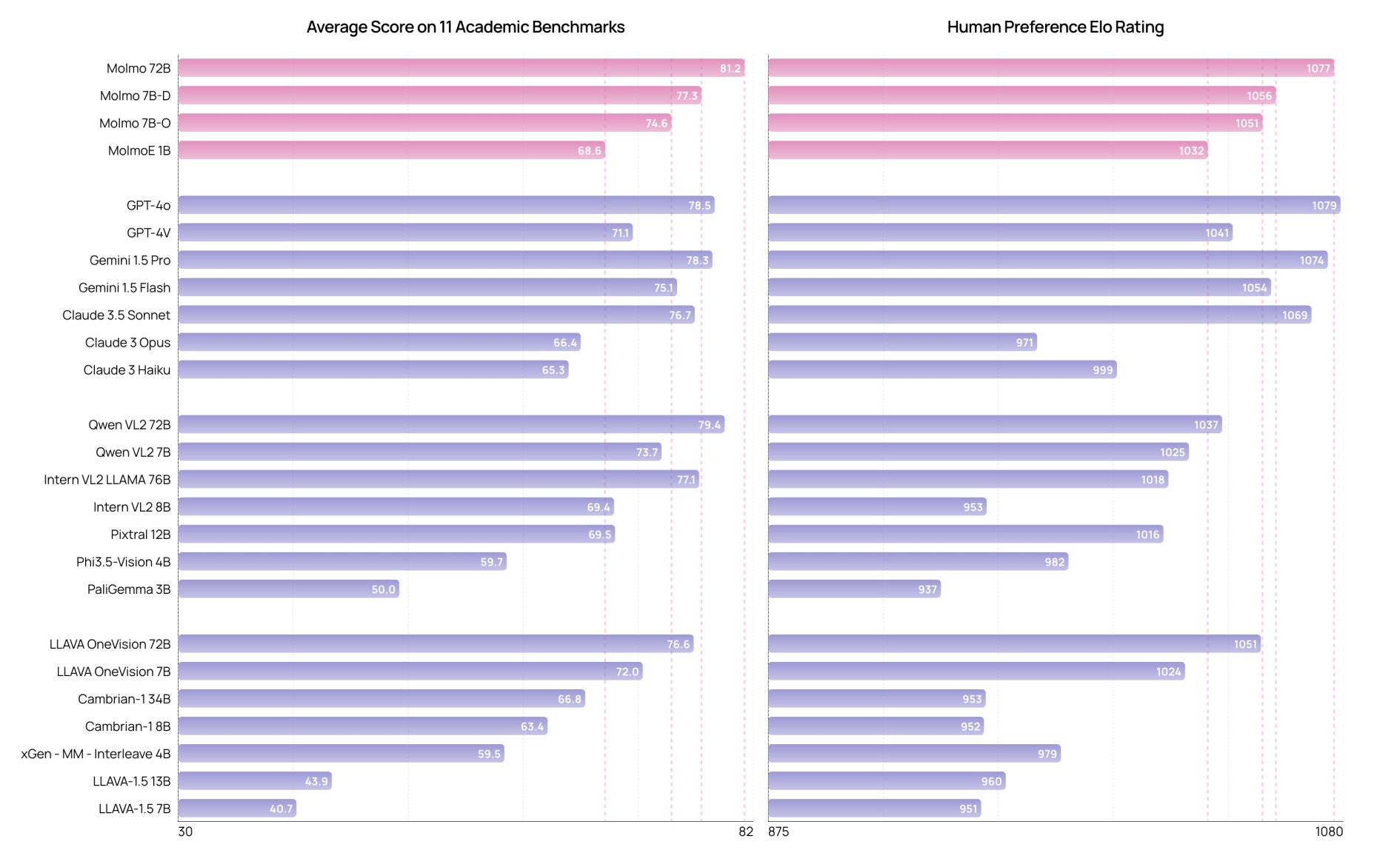
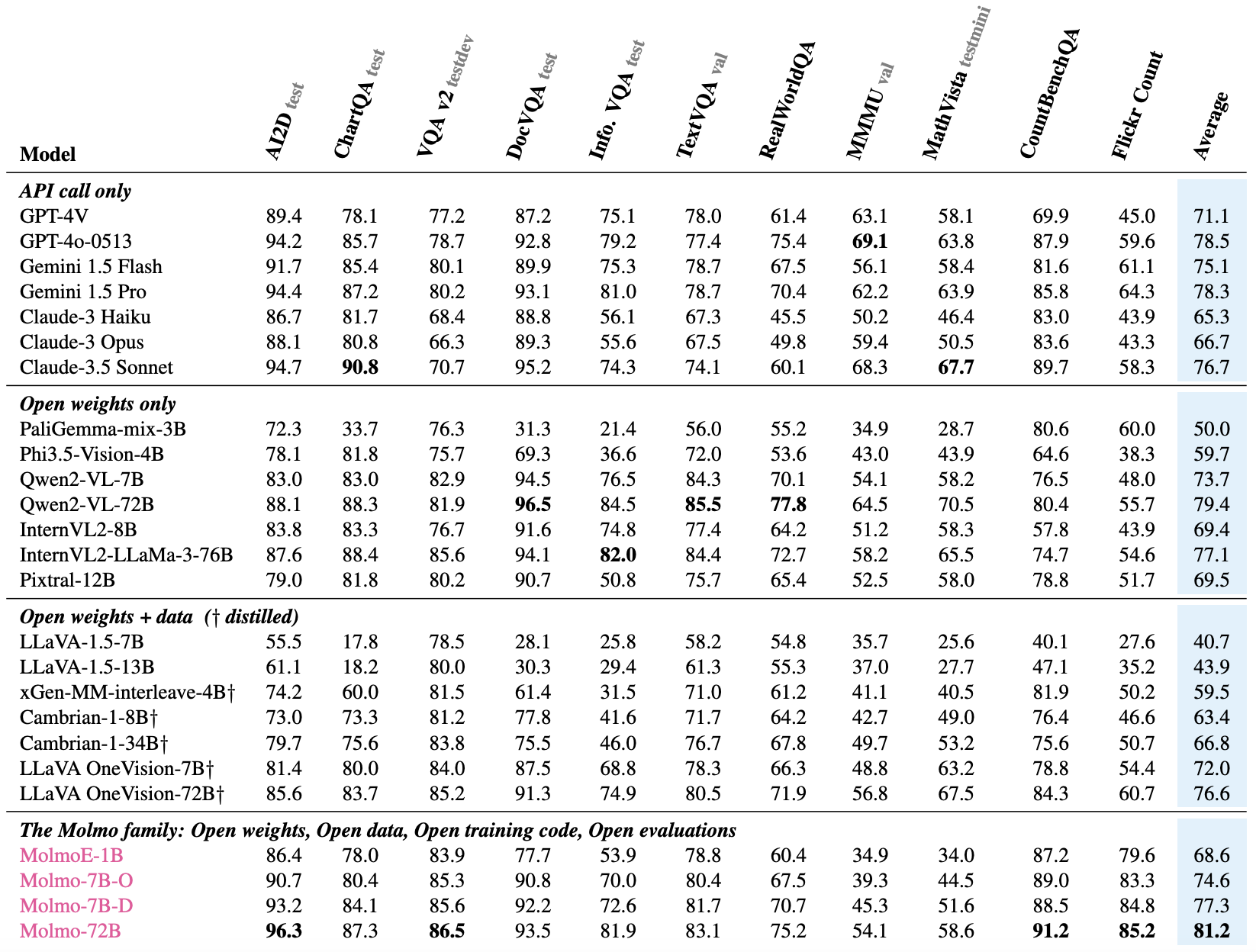
Molmo 모델군은 11개의 학술 벤치마크와 사용자 평가를 통해 성능을 검증함. MolmoE-1B는 GPT-4V와 거의 대등한 성능을 보였으며, Molmo-7B-O와 Molmo-7B-D는 GPT-4V와 GPT-4o 사이의 성능을 보임. 최고 성능 모델인 Molmo-72B는 학술 벤치마크에서 최고 점수를 기록하며, 인간 평가에서도 GPT-4o에 이어 2위를 기록함. Molmo-72B는 Gemini 1.5 Pro, Flash, Claude 3.5 Sonnet 등 최신 비공개 시스템을 능가함.
모델 구조
Molmo 모델 구조
Molmo의 아키텍처는 언어 모델과 비전 인코더를 결합한 간단하고 표준적인 설계를 따름. 4가지 주요 구성 요소로 이루어짐:
- 입력 이미지를 다중 스케일(multiscale) 및 다중 크롭(multi-crop) 이미지 집합으로 변환하는 전처리기(pre-processor).
- 각 이미지를 독립적으로 비전 토큰으로 변환하는 ViT 이미지 인코더.
- 비전 토큰을 MLP로 언어 모델의 입력 차원에 맞게 투영하고, 토큰 수를 줄이기 위해 풀링(pooling)하는 커넥터.
- 디코더 전용(decoder-only) 트랜스포머 LLM.

Molmo 모델 구성
- 모델 패밀리: 이 기본 구조에서 비전 인코더와 LLM의 선택에 따라 다양한 모델을 구성함. 학습 데이터와 학습 과정은 동일하지만, 최적화 학습률은 모델에 따라 조정됨.
- 비전 인코더: Molmo의 모든 공개 모델은 OpenAI의 ViT-L/14 336px CLIP 모델을 사용함. 이 모델은 고해상도 이미지를 처리하도록 학습되어 좋은 결과를 제공하며, MetaCLIP과 같은 연구에서 처음부터 재현 가능함.
- 언어 모델(LLM)은 모델 크기 및 공개 여부에 따라 선택할 수 있음:
- OLMo-7B-1024: 2024년 10월에 선발매된 백본(backbone), 추후 공개 예정.
- OLMoE-1B-7B: 가장 효율적인 모델.
- Qwen2 7B: 공개된 가중치 사용.
- Qwen2 72B: 최고 성능 모델.
데이터셋과 훈련 과정
훈련 과정
Molmo는 독립적으로 사전 학습된 비전 인코더와 언어 모델을 사용하며, 두 단계로 구성된 단순한 학습 과정을 거침:
- 캡션 생성을 위한 멀티모달 사전 학습: 새로운 캡션 데이터(PixMo-Cap)를 사용하여 이미지 캡션 생성 작업에 모델을 훈련.
- 지도 학습 기반 파인튜닝: 학술 데이터셋과 새로 수집한 PixMo-*(PixMo-star로 부르는 듯함) 데이터셋을 혼합하여 파인튜닝.
1단계: 캡션 생성
비전 인코더와 언어 모델을 연결하고, 무작위로 초기화된 커넥터와 함께 모든 모델 파라미터를 학습함. PixMo-Cap 데이터는 약 70개의 다양한 주제에 걸쳐 수집된 웹 이미지를 기반으로, 주석 작성자들이 60~90초 동안 이미지를 자세히 설명하는 방식으로 구축됨. 수집된 음성 데이터를 텍스트로 변환한 후 언어 모델을 사용해 텍스트 품질을 향상시키고, 이를 자연스러운 데이터 증강으로 활용함. 총 712,000개의 이미지와 약 130만 개의 캡션으로 훈련.
2단계: 지도 학습 기반 파인튜닝
캡션 생성 후, 다양한 학술 데이터셋과 새로 수집한 PixMo 데이터셋을 활용하여 파인튜닝함.
- PixMo-AskModelAnything: 사용자들이 모델에 물어볼 수 있는 다양한 질문을 반영한 데이터셋. 162,000개의 질문-답변 쌍과 73,000개의 이미지로 구성됨.
- PixMo-Points: 모델이 텍스트로 설명된 대상을 지목하고, 시각적 설명을 제공하며, 개수 세기를 지원하는 포인팅 데이터셋. 428,000개의 이미지에서 230만 개의 질문-포인팅 쌍을 수집함.
- PixMo-CapQA: 이미지의 실제 캡션을 바탕으로 언어 모델이 질문을 생성하고 답변을 제공하는 방식으로 생성된 214,000개의 질문-답변 쌍.
- PixMo-Docs: 코드가 포함된 텍스트 및 그림 중심의 이미지(문서, 차트, 테이블, 다이어그램)에서 230만 개의 질문-답변 쌍을 생성한 데이터셋.
- PixMo-Clocks: 다양한 시계 스타일과 시간을 나타내는 아날로그 시계 이미지를 사용하여 826,000개의 질문-답변 예시를 생성한 데이터셋.
- 학술 데이터셋: VQA v2, TextVQA, OK-VQA, ChartQA, DocVQA, InfographicVQA, AI2D, A-OKVQA, ScienceQA, TabMWP, ST-VQA, TallyQA, DVQA, FigureQA, PlotQA 등의 기존 학술 데이터셋으로 파인튜닝을 수행함.
Molmo 모델 평가
평가 방식
멀티모달 비전-언어 모델(VLM)의 성능 평가 방식은 빠르게 진화하고 있으며, 새로운 학술 벤치마크가 계속 등장하고 있음. 이러한 벤치마크는 특정 기술을 평가하는 데는 유용할 수 있지만, 벤치마크에서 지정한 형식의 답변을 요구하는 경우가 많아 대화형 환경에서는 적합하지 않음. 따라서 학술 벤치마크는 모델 성능을 부분적으로만 평가할 수 있음.
학술 벤치마크
11개의 널리 사용되는 학술 벤치마크에서 결과를 수집함. 기존 발표된 결과를 우선 사용했으나, 부족한 경우는 공개된 기술 보고서나 리더보드에서 데이터를 찾음. 데이터를 찾을 수 없을 경우 직접 계산했으며, 평가 과정의 세부 사항에 따라 큰 차이가 날 수 있어 재현이 어려운 문제도 있음.
제로샷(zero-shot)과 지도 학습
제로샷 성능과 지도 학습 성능의 구분은 모호함. 벤치마크의 학습 데이터를 대체할 수 있는 데이터를 새로 수집할 수 있기 때문이며, 학습 데이터가 공개되지 않으면 제로샷 성능을 평가하기 어려움.
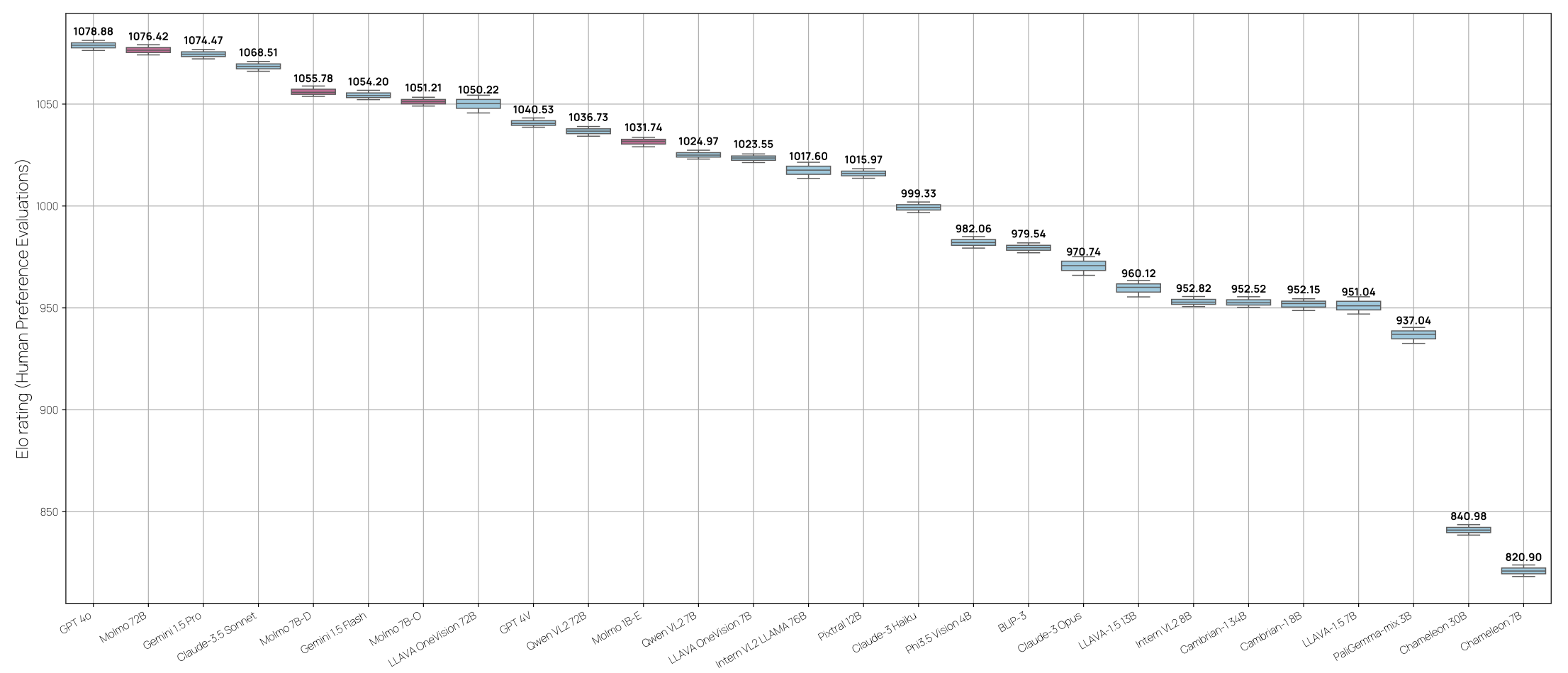
인간 평가
15,000개의 이미지 및 텍스트 프롬프트 쌍을 수집하여 다양한 VLM의 응답을 평가함. 870명의 평가자가 32만 5천 건 이상의 선호도를 제공했고, 이를 바탕으로 Elo 순위*를 계산함.
*본래 체스 경기에서 쓰이는 평가 방식을 차용한 것으로, 각 모델은 변동되는 점수를 가짐. 평가자는 두 모델의 답변을 비교하여 점수를 매기며 대상 모델이 높은 점수의 모델을 이길수록 더 높은 점수를 획득함.
평가 결과
- MolmoE-1B: OLMoE-1B-7B 기반의 경량 모델로, 학술 벤치마크와 Elo 평가에서 GPT-4V와 거의 동일한 성능을 보임.
- OLMo-7B-1024 및 Qwen2 7B 기반 모델들은 학술 벤치마크와 Elo 순위에서 GPT-4V와 GPT-4o 사이의 성능을 기록함.
- Qwen2 72B 기반의 최상위 모델은 학술 벤치마크에서 최고 점수를 기록하며, Elo 순위에서는 GPT-4o에 이어 2위를 차지함.
- Molmo의 최고 성능 모델은 Gemini 1.5 Pro, Flash, Claude 3.5 Sonnet 등 최신 비공개 시스템을 능가함.
- Molmo-72B는 AndroidControl 벤치마크에서 88.7%의 저수준 정확도(low-level accuracy)와 69.0%의 고수준 정확도(high-level accuracy)*를 기록하여, 기존 연구 결과와 유사한 성능을 보임.
*low-level accuracy는 개별 동작의 세밀함을, high-level accuracy는 여러 동작을 통합하여 더 큰 작업을 완수하는 능력을 나타냄.
'🟣 AI Study' 카테고리의 다른 글
| 아이폰의 애플 인텔리전스는 어떻게 학습되었을까? Apple Foundation Model(AFM) 논문 살펴보기 - 01 (2) | 2024.11.17 |
|---|---|
| Runway의 AI 영상 생성(Video Generation) 서비스 Gen-3 Alpha 사용해보기 (1) | 2024.10.26 |
| Phi-3.5와 PGVector 벡터 DB를 이용한 검색증강생성(RAG) 시스템 구축하기 (2) | 2024.09.26 |
| Meta, Llama 3.2 출시: 경량 모델(1B, 3B)과 비전(Vision) 모델 공개 (3) | 2024.09.26 |
| Microsoft의 Phi-3.5 모델 Mac Silicon 환경에서 구동하기 (0) | 2024.09.22 |




댓글