
2023.11.01 - [🔵 AI & ML] - 검색증강생성(RAG) 이해하기 - 01. 벡터 DB 기초 개념
TL;DR
이전 포스트에서 벡터 DB와 검색 증강 생성(RAG)에 대한 간단한 개념을 알아보았다. 그럼, 벡터 DB를 이용해 구축한 RAG 파이프라인을 어떻게 평가할 수 있을까?
언어 모델 자체의 평가에 있어서는 여러 지표가 알려져 있지만, 최근 주목받기 시작한 RAG 분야에 특화된 평가 지표는 확립되어 있지 않은 것 같다.
이 포스트에서는, RAG 파이프라인 평가 프레임워크인 Ragas를 참고하여 RAG의 평가 방법을 알아본다.
* 이해를 돕기 위한 의역이 포함될 수 있습니다.
Ragas
Ragas(Retrieval-Augmented Generation Assessment)는 RAG 파이프라인 평가 라이브러리를 함께 제공하는, Python 기반의 오픈소스 RAG 파이프라인 도구이다. AI 어플리케이션 구축에 쓰이는 LangChain, LlamaIndex 등과 연동되어, 간편한 평가가 가능하다.
Ragas에서는 RAG 파이프라인의 평가를 먼저 RAG 파이프라인의 각 구성 요소(component)를 개별적으로 평가하는 component-wise 평가 방법과 파이프라인의 전반적인 성능을 평가하는 데 사용하는 end-to-end 평가 방법을 함께 제공하는데, 이 포스트에서는 component-wise 평가 방법을 위주로 살펴본다.
Component-wise 평가 방법은 다시, 답변 생성(generation)과 문서 검색(retrieval)의 평가 방법으로 나뉜다.
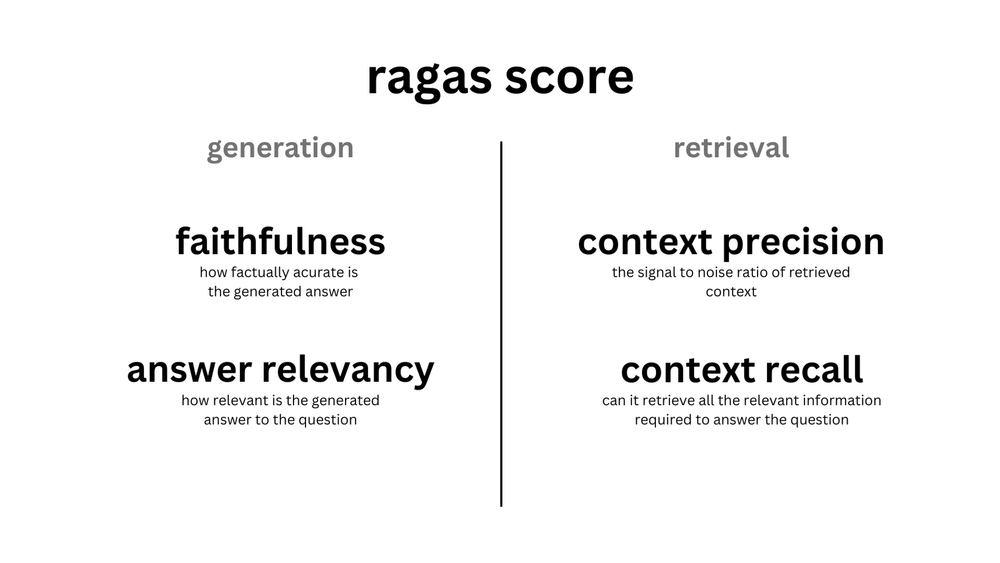
먼저 생성에 있어서는 검색된 문서와 생성된 답변 간의 관련성을 나타내는 faithfulness(충실성, 일관성)및 답변의 질문과의 관련도를 나타내는 answer relevance의 두 가지 지표가 있다. 검색에 있어서는 질문에 대해 검색한 문서인 context에 대한 precision(정밀도)과 recall(재현률)이 있다. 그림엔 나와있지 않지만, 검색 관련 지표에 context relavance라는 지표도 있다.
Faithfulness
Faithfulness는 주어진 context*에 대한 생성된 답변의 일관성을 측정한다. faithfulness는 생성된 답변과 context를 비교하여 계산되며, (0, 1) 범위로 스케일링되는 높을수록 좋은 지표이다.
답변에 포함된 주장을 대부분 주어진 context로부터 유추할 수 있는 경우, 생성된 답변은 faithful한 것으로 간주된다. 이를 계산하기 위해 먼저 생성된 답안에서 일련의 정보 단위를 식별한다. 그런 다음 이러한 각 정보를 주어진 context에 포함된 정보와 교차 검사하여 정보를 해당 context에서 유추할 수 있는지 판단한다. Faithfulness 점수는 다음과 같이 계산된다.
$$ \text{faithfulness} = \frac{\text{context로부터 추론할 수 있는 정보의 수}}{\text{생성된 답변에 포함된 정보의 수}}$$
* RAG 파이프라인에서, context는 보통 지식 데이터로부터 검색된 문서들을 의미한다. 생성 모델은 검색된 문서를 대화의 주요한 맥락(context)으로 생각하여 답변을 생성하게 된다.
공식 문서의 예제로 faithfulness 지표를 이해해보자.
질문: 아인슈타인은 언제, 어디서 태어났나요?
Context(검색된 문서): 알버트 아인슈타인(1879년 3월 14일 출생)은 독일 태생의 이론 물리학자로, 역사상 가장 위대하고 영향력 있는 과학자 중 한 명으로 널리 알려져 있습니다.
Faithfulness가 높은 답변: 아인슈타인은 1879년 3월 14일 독일에서 태어났습니다.
Faithfulness가 낮은 답변: 아인슈타인은 1879년 3월 20일 독일에서 태어났습니다.
다소 단순한 예제이긴 하지만, 첫 번째 질문이 context와 더 일치한다고 할 수 있다. 만약 context에서 아인슈타인의 출생을 3월 20일로 표기했다면, 이것이 잘못된 정보라 하더라도 faithfulness가 높은 답변은 두 번째 답변이 될 것이다.
Answer Relavance
다음은 answer relavance(답변 관련도)이다. Answer relavance는 생성된 답변이 주어진 프롬프트(질문)와 얼마나 관련성이 있는지를 평가한다. 불완전하거나 중복된 정보를 포함하는 답변에는 낮은 점수가 부여된다. 이 지표는 질문과 답변을 함께 사용하여 0에서 1 사이의 값으로 계산되며, 점수가 높을수록 관련성이 높음을 나타낸다.
Answer relavance의 중요한 점은, 답변의 관련성을 평가할 때 답변의 사실 여부보다는 답변의 완전성이나 중복된 정보의 서술 여부로 점수를 매긴다는 것이다. Answer relavance를 계산하기 위해, LLM을 이용해 역으로 생성된 답변에 적합한 질문을 여러 번 생성한다. 이렇게 생성된 질문과 원래 질문 간의 평균 코사인 유사도(cosine similarity)를 측정한다.
LLM이 생성된 답변이 질문과 관련이 있다면, LLM은 답변으로부터 처음 사용자가 입력한 질문을 생성할 수 있어야 한다는 것이 answer relavance 지표의 핵심 아이디어이다. 공식 문서의 예제로 answer relavance 지표를 이해해보자.
질문: 프랑스는 어디에 있으며 수도는 무엇인가요?
Answer relavance가 낮은 답변: 프랑스는 서유럽에 있습니다.
Answer relavance가 높은 답변: 프랑스는 서유럽에 있으며 파리가 수도입니다.
두 번째 답변으로부터 원래 질문을 유추하기 더 쉽다고 생각할 수 있다. 첫 번째 답변은 수도에 대한 정보가 누락되어 질문을 정확히 유추하기 어렵다.
Context Precision
다음은 검색에 관련된 지표로, context precision이 있다. Context precision는 context에 존재하는 ground-truth와 관련된 항목을 높은 순위로 잘 검색해 왔는지의 여부를 평가하는 지표이다. 질문과 context를 이용해 0에서 1 사이의 값으로 계산되며, 점수가 높을수록 정확도가 높음을 의미한다.
* ground-truth는 미리 레이블링되어 제공되는, 우리가 모델로부터 얻고자 하는 정답 정보를 말한다. 약자로 GT라고도 표현한다.
Context precision의 계산 과정은 조금 복잡해보일 수 있는데, 공식 문서에서 표현된 계산식은 다음과 같다.
$$ \text{precision@k} = {\text{true positives@k} \over (\text{true positives@k} + \text{false positives@k})} $$
$$ \text{context precision@k} = {\sum {\text{precision@k}} \over \text{상위 K개 결과 중 관련 항목 수}} $$
식을 언뜻 보면 헷갈리는 부분이 있는데, precision@k에서의 k와 context precision의 분모의 대문자 K가 다른 의미를 가지는 것 같다. 소문자 k는 context에 포함된 모든 chunk 수를 의미한다. 대문자 K는 별도의 설명은 없는데, RAG 파이프라인이 검색하여 가져온 context의 수, 또는 가져온 context에서 유사도 순으로 순위를 매겨 가져온 상위 K개의 context를 의미하는 것으로 보인다.
이와 관련된 한 github 이슈를 보면, context precision에서의 ground-truth 활용에 대한 토론도 있었던 것 같다. 이 때문에 context utilization이라는 새로운 지표를 만든 것 같은데, 아직 개발 중인 사항으로 보여 context precision 및 context utilization 지표의 정확한 의미나 계산에 대한 판단은 보류하고자 한다.
어쨌든 일반적인 precision의 의미를 생각했을 때, context precision 지표의 핵심은 '질문에 대하여 검색하여 가져온 문서 중, 질문에 대한 답변과 관련있는 문서의 비율'이 이라고 할 수 있다.
Context Recall
다음은 context recall인데, 사전에 정답으로 annotated된 답변을 ground-truth로 지정하고 이 답변의 문장 중 context로부터 추론할 수 있는 문장의 비율을 측정한다. 0과 1사이의 값을 가지고 더 높은 값이 더 높은 성능을 나타낸다. 식으로는 다음과 같이 표현할 수 있다.
$$ \text{context recall} = {|\text{context에서 추론 가능한 GT 답변 내 문장 수}| \over |\text{GT 답변 내 문장 수}|} $$
공식 문서의 예제를 통해 context recall을 이해해보자.
질문: 프랑스는 어디에 있으며 수도는 무엇인가요?
Ground-truth(GT): 프랑스는 서유럽에 속하며 수도는 파리입니다.
Context recall이 높은 context: 서유럽에 있는 프랑스는 중세 도시, 고산 마을, 지중해 해변을 아우르는 나라입니다. 수도인 파리는 패션 하우스, 루브르 박물관을 비롯한 클래식 미술관, 에펠탑과 같은 기념물로 유명합니다.
Context recall이 낮은 context:
서유럽에 위치한 프랑스는 중세 도시, 고산 마을, 지중해 해변을 아우르는 나라입니다. 이 나라는 와인과 세련된 요리로도 유명합니다. 라스코(Lascaux)의 고대 동굴 벽화, 리옹(Lyon)의 로마 극장, 광활한 베르사유 궁전은 프랑스의 유구한 역사를 증명합니다.
첫 번째 답변의 경우 GT의 문장 중 2개의 문장에 대한 내용을 모두 추론할 수 있으므로 1의 context recall값을 가지고, 두 번째 답변의 경우 1개 문장만을 추론할 수 있으므로 0.5의 context recall 값을 가진다고 할 수 있다.
여기서 faithfulness의 지표와 context recall을 혼동할 수 있는데, faithfulness는 ground-truth와의 일치를 고려하는 것이 아니라 context와 최종 생성된 답변과의 일치도에 중점을 둔 지표라는 점을 기억하자. Context recall은 ground-truth와의 일치도를 고려하여 정확한 정보를 검색해왔는지를 평가하는 지표이다.
Context Relavancy
다음은 context relavancy이다. Context relavancy는 검색한 context가 질문과 관련이 있는지를 측정한다. 0과 1사이의 값을 가지고, 높을 수록 관련성이 높다고 판단한다. Context relavancy는 다음과 같이 계산한다.
$$ \text{context relevancy} = {|S| \over |\text{검색한 context에 포함된 문장 수}|} $$
S는 정의하기 나름이라고 생각할 수도 있고, 질문과 관련된 문장의 수로 이해할 수 있을 것 같다. S를 어떻게 계산할지는 궁금하지만, 지표 자체의 개념은 간단하다. 실제로 지표를 사용해보면 좀 더 정확히 알 수 있을 것 같다.
마치며
Ragas에서 제안한 RAG 파이프라인 평가 방법은 충분히 타당하다고 보이지만, 이 지표를 객관적으로 비교할 수 있는 특정 데이터셋이나 지표에서 명시하는 관련성 판단 방법이 함께 제안되었는지는 명확하지 않다.
어떤 지표는 LLM을 평가 과정에서 사용하는 것 같은데, 이 경우 사용하는 모델이나 프롬프트 정보 또한 공식 문서에 제공되어야 할 것이다. 추후 실제로 이 지표들을 사용해보고, 또 글을 작성해볼 계획이다.
'🟣 AI Study' 카테고리의 다른 글
| OpenAI의 동영상 생성 모델 'Sora' Technical Report 읽어보기 (0) | 2024.02.17 |
|---|---|
| 검색증강생성(RAG) - 벡터 인덱스 기초 및 IVF (0) | 2024.02.12 |
| LLM 이해하기 - LLM의 기초 개념 (3) | 2024.01.14 |
| Microsoft, 2.7B의 경량 규모 언어 모델 출시: Phi-2 (2) | 2024.01.10 |
| 경량화 LLM을 이용한 SQL 생성기를 만들어보자 (1) | 2024.01.06 |




댓글