
* 이해를 돕기 위한 의역이 포함될 수 있습니다.
* 각주나 이미지, 영상 등의 보조 자료는 원문 링크에서 확인 가능합니다.
원문 링크: https://openai.com/research/video-generation-models-as-world-simulators
Video generation models as world simulators
세계 시뮬레이터로서의 비디오 생성 모델
February 15, 2024
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
- OpenAI는 영상 데이터에 대한 대규모 생성 모델 학습을 연구함
- 특히 텍스트-조건부 확산(text-conditional diffusion) 모델에 다양한 길이, 해상도, 화면 비율의 동영상과 이미지를 공동으로 학습시킴
- 영상 및 이미지 잠재 코드(latent codes)의 시공간 패치에서 작동하는 트랜스포머 아키텍처를 활용함
- 가장 큰 모델인 Sora는 최대 1분 분량의 고화질 동영상을 생성할 수 있음
- 연구 결과는 영상 생성 모델을 확장시키는 것이 물리적 세계의 범용 시뮬레이터를 구축하는 데 있어 유망한 방법임을 시사함
This technical report focuses on our method for turning visual data of all types into a unified representation that enables large-scale training of generative models, and qualitative evaluation of Sora’s capabilities and limitations. Model and implementation details are not included in this report.
- 이 기술 보고서는 생성 모델의 대규모 학습과 Sora의 능력과 한계에 대한 정성적인 평가가 가능하도록 다양한 형태의 시각 데이터를 통합적 표현으로 나타내는 방법을 설명하는 데에 초점을 두고 있음
- 모델 파일이나 구현의 상세 사항은 보고서에 포함되어 있지 않음
Much prior work has studied generative modeling of video data using a variety of methods, including recurrent networks, generative adversarial networks, autoregressive transformers and diffusion models. These works often focus on a narrow category of visual data, on shorter videos, or on videos of a fixed size. Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.
- 생성 모델링에 대한 많은 선행 연구들은 순환 신경망, 적대적 생성 신경망(GAN), 자가회귀 트랜스포머, 확산 모델 등의 다양한 방법을 이용해 왔음
- 이 연구들은 시각 데이터의 좁은 카테고리를 다루거나, 길이가 짧거나 고정된 크기의 영상에 초점을 둔 경우가 많음
- Sora는 시각 데이터에 대한 범용 모델로, 최대 1분의 HD(high definition) 영상의 수준까지 영상 길이, 종횡비, 해상도를 다양하게 설정하여 이미지나 영상을 생성할 수 있음
Turning visual data into patches
시각 데이터를 패치로 변환
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data. The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data. We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.
- 연구진은 인터넷 규모의 데이터에 대한 훈련을 통해 범용 모델로서의 기능을 습득하는 대규모 언어 모델에서 영감을 얻음
- LLM 패러다임의 성공에는 코드, 수학 및 자연어와 같은 다양한 형태의 텍스트 데이터를 정교하게 통합한 토큰을 사용한 것이 부분적으로 기여함
- 이 연구에서는 시각 데이터 생성 모델이 이러한 이점을 언어 모델로부터 어떻게 차용할 수 있었는지 살펴봄
- LLM에는 텍스트 토큰이 있는 반면, Sora에는 시각 패치(visual patches)가 있음
- 패치는 앞선 연구에서 시각 데이터 모델에 효과적인 표현으로 알려짐
- 패치는 다양한 유형의 동영상과 이미지에 대한 생성 모델을 훈련하는 데 확장성이 뛰어나고 효과적임
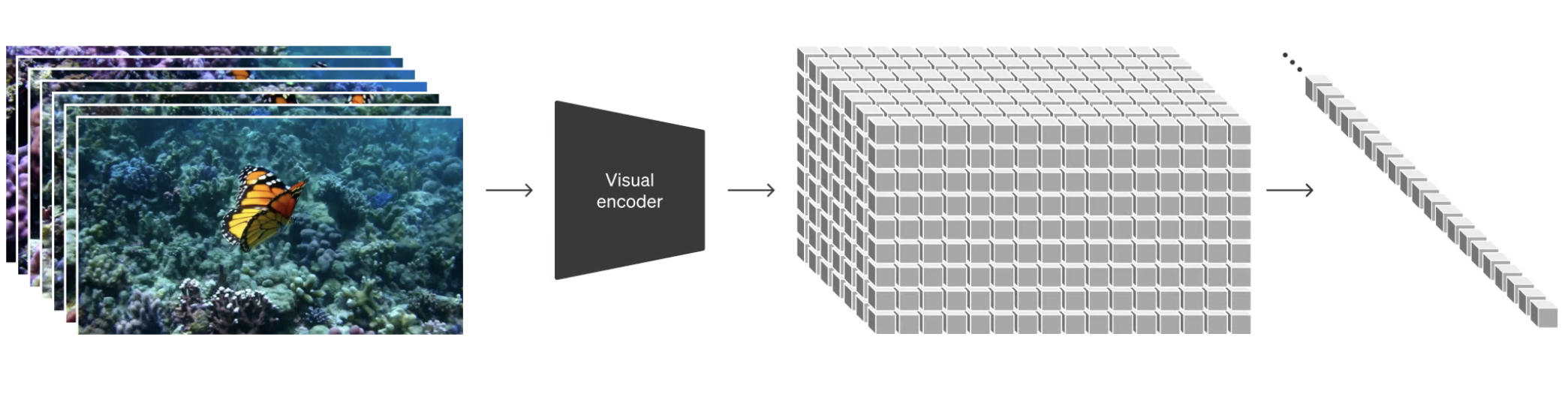
At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space and subsequently decomposing the representation into spacetime patches.
- 높은 수준에서는, 먼저 동영상을 저차원 잠재 공간(latent space)으로 압축한 다음 시공간 패치(spacetime patches)로 표현을 분해하여 동영상을 패치로 변환함
Video compression network
비디오 압축 네트워크
We train a network that reduces the dimensionality of visual data. This network takes raw video as input and outputs a latent representation that is compressed both temporally and spatially. Sora is trained on and subsequently generates videos within this compressed latent space. We also train a corresponding decoder model that maps generated latents back to pixel space.
- 학습의 첫 단계로, 시각 데이터의 차원을 줄이는 네트워크를 훈련
- 이 네트워크는 원본 영상을 입력으로 받아 시간적, 공간적으로 압축된 잠재적 표현을 출력(이를 인코더 모델이라 할 수 있음)
- Sora는 이 압축된 잠재 공간 내에서 영상을 학습한 후 생성을 수행
- 생성된 잠재 표현을 다시 픽셀 공간으로 매핑하는 디코더 모델을 학습시킴
Spacetime Latent Patches
시공간 잠재 패치
Given a compressed input video, we extract a sequence of spacetime patches which act as transformer tokens. This scheme works for images too since images are just videos with a single frame. Our patch-based representation enables Sora to train on videos and images of variable resolutions, durations and aspect ratios. At inference time, we can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid.
- 압축된 입력 영상이 주어지면, 트랜스포머의 토큰 역할을 하는 시공간 패치 시퀀스를 추출
- 이미지는 단일 프레임의 영상에 불과하기 때문에 이 방식은 이미지에서도 작동함
- 패치 기반의 표현을 통해 Sora는 다양한 해상도, 길이, 화면 비율의 영상과 이미지를 학습할 수 있음
- 추론 시에는, 무작위로 초기화된 패치를 적절한 크기의 격자(grid)에 배열하여 생성된 영상의 크기를 제어할 수 있음
Scaling transformers for video generation
동영상 생성을 위한 트랜스포머 스케일링
Sora is a diffusion model given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer. Transformers have demonstrated remarkable scaling properties across a variety of domains, including language modeling, computer vision, and image generation.
- Sora는 인위적으로 노이즈를 포함시킨 패치(및 텍스트 프롬프트와 같은 조건 정보)를 입력으로 받는 확산 모델(diffusion model)로, 모델의 노이즈가 없는, 원본의 "깨끗한(clean)" 패치를 예측하도록 학습됨
- 중요한 점은 Sora가 확산 트랜스포머라는 점으로, 트랜스포머는 언어 모델링, 컴퓨터 비전, 이미지 생성 등 다양한 영역에서 놀라운 확장성을 입증해 왔음

In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.
- 이 연구에서는 확산 트랜스포머가 영상 모델로도 효과적으로 확장된다는 사실을 발견함
- 아래는 훈련이 진행됨에 따라 고정된 시드와 입력이 있는 영상 샘플을 비교한 것으로, 훈련 연산이 증가함에 따라 샘플 품질이 현저히 향상되는 것을 볼 수 있음

Variable durations, resolutions, aspect ratios
가변 길이, 해상도, 화면 비율
Past approaches to image and video generation typically resize, crop or trim videos to a standard size – e.g., 4 second videos at 256x256 resolution. We find that instead training on data at its native size provides several benefits.
- 이미지 및 동영상 생성에 대한 과거의 일반적인 접근 방식은, 동영상을 설정한 기준 크기(예: 256x256 해상도의 4초 동영상)로 크기를 조정하거나 자르거나 트리밍(trimming)하는 것이었음
- 이러한 방법 대신, 기본 크기로 데이터를 학습하면 몇 가지 이점을 얻을 수 있음
Sampling flexibility
샘플링 유연성
Sora can sample widescreen 1920x1080p videos, vertical 1080x1920 videos and everything inbetween. This lets Sora create content for different devices directly at their native aspect ratios. It also lets us quickly prototype content at lower sizes before generating at full resolution—all with the same model.
- Sora는 와이드스크린 1920x1080p 영상, 세로 1080x1920 영상과 그 사이 범위의 모든 영상을 샘플링할 수 있음
- 이를 통해 Sora는 다양한 디바이스의 기본 화면 비율에 맞춘 콘텐츠를 곧바로 제작할 수 있음
- 또한, 동일한 모델로 전체 해상도 영상을 생성하기 전에 더 작은 크기의 콘텐츠를 프로토타입으로 빠르게 제작할 수 있음

Improved framing and composition
향상된 프레이밍 및 구도
We empirically find that training on videos at their native aspect ratios improves composition and framing. We compare Sora against a version of our model that crops all training videos to be square, which is common practice when training generative models. The model trained on square crops (left) sometimes generates videos where the subject is only partially in view. In comparison, videos from Sora (right)s have improved framing.
- 연구진은 실험을 통해 기본 화면 비율로 동영상을 학습하면 구도와 프레임이 개선된다는 사실을 발견함
- 생성 모델을 훈련할 때 일반적으로 사용되는, 모든 훈련 동영상을 정사각형으로 자르는 모델과 Sora를 비교하는 실험을 수행
- 정사각형 크롭으로 훈련된 모델(왼쪽)은 피사체가 부분적으로만 보이는 동영상을 생성하는 경우가 있음
- 이에 비해, Sora(오른쪽)의 동영상은 프레임이 개선됨

Language understanding
언어 이해
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 330 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
- text-to-video 생성 시스템을 학습시키기 위해선, 대량의 텍스트 캡션(caption, 동영상을 묘사하는 텍스트)이 포함된 동영상 데이터셋이 필요
- 연구진은 DALL-E 330에 도입된 리캡셔닝(re-captioning) 기법을 동영상에 적용
- 먼저 설명력이 높은 캡션 모델을 학습시킨 다음 이를 사용하여 학습 세트의 모든 영상에 대한 텍스트 캡션을 생성
- 설명력이 높은 영상 캡션을 학습하면 ,텍스트 충실도는 물론 영상의 전반적인 품질이 향상된다는 사실을 발견
- 또한, DALL-E 3에서처럼 짧은 사용자의 프롬프트를 더 길고 상세한 캡션으로 변환하여 비디오 모델에 전송하는 데에 GPT를 활용할 수 있음
- 이를 통해 Sora는 사용자 프롬프트를 정확하게 따르는 고품질 동영상을 생성할 수 있음

Prompting with images and videos
이미지와 영상에 대한 프롬프팅
All of the results above and in our landing page show text-to-video samples. But Sora can also be prompted with other inputs, such as pre-existing images or video. This capability enables Sora to perform a wide range of image and video editing tasks—creating perfectly looping video, animating static images, extending videos forwards or backwards in time, etc.
- 위의 자료와 홈페이지의 랜딩 페이지에 포함된 모든 생성 결과는 text-to-video 모델의 샘플을 보여줌
- 하지만, (텍스트 외에도) 기존 이미지나 동영상과 같은 다른 입력을 입력할 수 있음
- 이를 통해 Sora는 반복되는 비디오 제작, 정적 이미지 애니메이션, 비디오 앞·뒤로의 시간적 확장 등 다양한 이미지 및 비디오 편집 작업을 완벽하게 수행할 수 있음
Animating DALL·E images
DALL-E의 이미지를 애니메이팅하기
Sora is capable of generating videos provided an image and prompt as input. Below we show example videos generated based on DALL·E 231 and DALL·E 330 images.
- Sora는 이미지와 프롬프트를 입력으로 제공하여 동영상을 생성할 수 있음
- 아래는 DALL-E 231 및 DALL-E 330 이미지를 기반으로 생성된 비디오의 예시


Extending generated videos
생성된 동영상을 확장하기
Sora is also capable of extending videos, either forward or backward in time. Below are four videos that were all extended backward in time starting from a segment of a generated video. As a result, each of the four videos starts different from the others, yet all four videos lead to the same ending.
We can use this method to extend a video both forward and backward to produce a seamless infinite loop.
- Sora는 동영상을 앞뒤로 확장할 수도 있음
- 아래는 모두 생성된 동영상의 한 부분에서 시작하여 시간을 역방향으로 연장한 4개의 동영상
- 결과적으로, 네 개의 동영상은 각각 시작은 다르지만 모두 동일한 엔딩으로 이어짐
- 이 방법을 사용하면 동영상을 앞뒤로 확장하여 매끄러운 무한 루프(loop)를 만들 수 있음
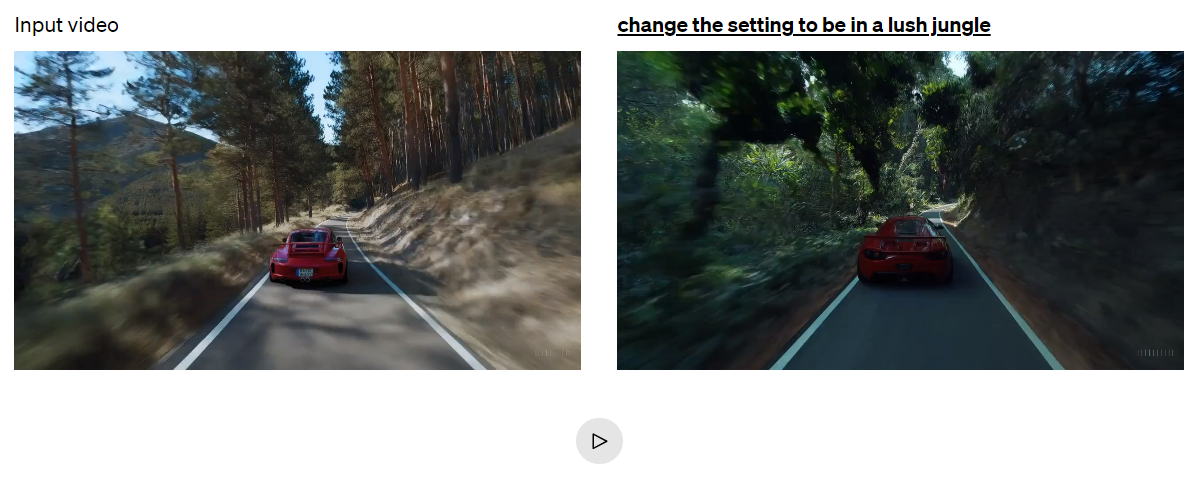
Video-to-video editing
video-to-video 편집
Diffusion models have enabled a plethora of methods for editing images and videos from text prompts. Below we apply one of these methods, SDEdit,32 to Sora. This technique enables Sora to transform the styles and environments of input videos zero-shot.
- 확산 모델을 통해 텍스트 프롬프트에서 이미지와 동영상을 편집할 수 있는 다양한 방법이 가능해짐
- 아래에서는 이러한 방법 중 하나인 SDEdit32를 Sora에 적용
- 이 기법을 통해 Sora는 입력된 동영상의 스타일과 환경을 제로샷(zero-shot)으로 변환할 수 있음
Connecting videos
영상 연결하기
We can also use Sora to gradually interpolate between two input videos, creating seamless transitions between videos with entirely different subjects and scene compositions. In the examples below, the videos in the center interpolate between the corresponding videos on the left and right.
- Sora를 사용하여 두 입력 비디오 사이를 점진적으로 보간하여(interpolate), 완전히 다른 주제와 장면 구성을 가진 영상 간에 매끄러운 전환을 만들 수 있음
- 아래 예시에서 중앙의 동영상은 왼쪽과 오른쪽의 해당 동영상 사이에 보간을 적용

Image generation capabilities
이미지 생성 능력
Sora is also capable of generating images. We do this by arranging patches of Gaussian noise in a spatial grid with a temporal extent of one frame. The model can generate images of variable sizes—up to 2048x2048 resolution.
- Sora는 이미지도 생성할 수 있음
- 이미지 생성은, 가우시안 노이즈(Gaussian noise) 패치를 단일 프레임의 시간적 범위로 공간 그리드에 배열하는 방식으로 수행
- 모델은 최대 2048x2048 해상도의 다양한 크기의 이미지를 생성할 수 있음

Emerging simulation capabilities
창발적인 시뮬레이션 능력
We find that video models exhibit a number of interesting emergent capabilities when trained at scale. These capabilities enable Sora to simulate some aspects of people, animals and environments from the physical world. These properties emerge without any explicit inductive biases for 3D, objects, etc.—they are purely phenomena of scale.
- 비디오 모델을 대규모로 학습시키면 여러 가지 흥미로운 창발적 능력(mergent capabilities)을 보임
- 이러한 능력을 통해 Sora는 실제 세계의 사람, 동물, 환경의 일부 측면을 시뮬레이션할 수 있음
- 이러한 특징은 3D, 객체 등에 대해 어떤 명시적인 귀납적 편향(inductive biases) 없이 순전히 모델의 규모에 따른 현상에서 나타남
3D consistency. Sora can generate videos with dynamic camera motion. As the camera shifts and rotates, people and scene elements move consistently through three-dimensional space.
3D 영상에서의 일관성
- Sora는 역동적인 카메라 움직임으로 동영상을 생성할 수 있음
- 카메라가 이동하고 회전함에 따라 사람과 장면 요소가 3차원 공간에서 일관되게 움직임

Long-range coherence and object permanence. A significant challenge for video generation systems has been maintaining temporal consistency when sampling long videos. We find that Sora is often, though not always, able to effectively model both short- and long-range dependencies. For example, our model can persist people, animals and objects even when they are occluded or leave the frame. Likewise, it can generate multiple shots of the same character in a single sample, maintaining their appearance throughout the video.
긴 범위에서의 일관성 및 객체 지속성
- 동영상 생성 시스템의 중요한 과제는 긴 동영상을 샘플링할 때 시간적 일관성을 유지하는 것
- Sora는 항상 그런 것은 아니지만, 종종 단거리 및 장거리 종속성을 모두 효과적으로 모델링할 수 있는 것으로 나타남
- 예를 들어, 사람, 동물, 사물이 가려지거나 프레임을 벗어난 경우에도 모델링을 지속시킬 수 있음
- 또한, 단일 샘플에서 동일한 캐릭터의 여러 샷을 생성하여 비디오 전체에 걸쳐 그 모습을 유지할 수 있음

Interacting with the world. Sora can sometimes simulate actions that affect the state of the world in simple ways. For example, a painter can leave new strokes along a canvas that persist over time, or a man can eat a burger and leave bite marks.
세상과 상호작용하기
- Sora는 때때로 간단한 방법으로 세상의 상태에 영향을 미치는 행동을 시뮬레이션할 수 있음
- 예를 들어, 캔버스에 시간이 지나도 지속되는 새로운 획을 남기거나 햄버거를 먹고 물린 자국을 남길 수 있음

Simulating digital worlds. Sora is also able to simulate artificial processes–one example is video games. Sora can simultaneously control the player in Minecraft with a basic policy while also rendering the world and its dynamics in high fidelity. These capabilities can be elicited zero-shot by prompting Sora with captions mentioning “Minecraft.”
디지털 세계 시뮬레이션
- Sora는 비디오 게임과 같은 인공적인 프로세스도 시뮬레이션할 수 있음
- Sora는 Minecraft에서 게임의 규칙에 따라 플레이어를 제어하는 동시에, 게임 세계와 그 물리적 속성을 충실하게 렌더링할 수 있음
- 이러한 기능은 "Minecraft"라는 캡션으로 Sora에게 메시지를 표시해 제로샷(zero-shot) 생성을 유도할 수 있음

These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them.
- 이러한 기능은 동영상 모델의 지속적인 확장이 물리적 및 디지털 세계와 그 안에 존재하는 사물, 동물, 사람에 대한 고성능 시뮬레이터를 개발하는 데 유망한 경로임을 시사함
Discussion
고찰
Sora currently exhibits numerous limitations as a simulator. For example, it does not accurately model the physics of many basic interactions, like glass shattering. Other interactions, like eating food, do not always yield correct changes in object state. We enumerate other common failure modes of the model—such as incoherencies that develop in long duration samples or spontaneous appearances of objects—in our landing page.
- 현재 Sora는 시뮬레이터로서 많은 한계를 드러내고 있음
- 예를 들어, 유리가 깨지는 것과 같은 기본적인 상호작용의 물리학을 정확하게 모델링하지 못함
- 음식을 먹는 것과 같은 상호작용에 대해서도, 물체 상태에 대해 올바른 변화를 나타내지 못함
- 이 외에도, 길이가 긴 샘플에서 발생하는 불일치 현상이나 물체의 갑작스러운 출현과 같은 모델의 일반적인 실패 양상을 랜딩 페이지에서 보여주고 있음
We believe the capabilities Sora has today demonstrate that continued scaling of video models is a promising path towards the development of capable simulators of the physical and digital world, and the objects, animals and people that live within them.
- 현재 Sora의 능력은 영상 모델의 지속적인 확장이 물리적 세계와 디지털 세계, 그리고 그 안에 존재하는 사물, 동물, 사람에 대한 시뮬레이터를 개발하는 데 있어 유망한 방법이라는 것을 입증함
'🟣 AI Study' 카테고리의 다른 글
| ChatGPT에 질문을 해도 반응이 없을 경우 해결 방법 (0) | 2024.03.12 |
|---|---|
| 검색증강생성(RAG) - 그래프 기반 벡터 인덱스 HNSW(Hierarchical Navigable Small World) (0) | 2024.02.25 |
| 검색증강생성(RAG) - 벡터 인덱스 기초 및 IVF (0) | 2024.02.12 |
| 검색증강생성(RAG) - Ragas를 이용한 RAG 파이프라인 평가 (0) | 2024.01.27 |
| LLM 이해하기 - LLM의 기초 개념 (3) | 2024.01.14 |




댓글